OpenLedger: 데이터 기여와 보상이 가능한 확장형 AI 플랫폼


이 리포트는 Web3 리서처 Teng Yan이 쓴 글(Hugging Face가 AI 데이터 경제와 결합된다면 어떨까?, 2025.03.05)을 쟁글에서 번역하여 작성하였습니다.
(Translated by Lyne Choi)
TL;DR
- AI의 미래는 "모든 것을 다 할 수 있는 단 하나의 모델"이 아니라 수천 개의 도메인 특화 AI가 주도한다.
- AI는 고품질의 도메인 특화 데이터가 있을 때 발전하지만, 정작 이런 데이터를 생산하는 전문가들은 보상을 거의 받지 못한다.
- OpenLedger는 AI를 '유튜브 시대'로 이끌고 있다. 즉, 전문화된 데이터의 기여자들이 직접적으로 수익을 창출할 수 있게 한다.
- Payable AI는 AI 모델 사용자가 데이터 제공자의 데이터를 활용할 때마다 직접 보상하는 구조다. OpenLedger는 Hugging Face의 개방형 접근 방식을 유지하면서도 여기에 경제적 보상과 책임성을 추가했다.
- DataNets(데이터넷)는 탈중앙화된 데이터 저장소로, 기여자들이 전문화된 고품질 데이터를 제공하고, 모델이 이를 사용할 수 있도록 한다. 이 저장소는 EVM 호환 레이어2(L2) 위에서 작동한다.
- Proof of Attribution(기여 증명, PoA)은 OpenLedger가 가진 핵심 기술이다. 이는 특정 데이터가 AI의 결과물에 얼마나 기여했는지를 추적하고 검증한다.
- AI 분야에서 데이터 기여를 정확히 측정하는 것은 매우 어렵다. OpenLedger는 최신 연구 성과를 실제로 적용 가능하게 만들기 위해 어려운 작업을 수행하고 있으며, 특히 전문화된 모델에서 효과적인 접근 방식을 제시하고 있다.
들어가며
모든 의사, 변호사, 엔지니어가 똑같은 매뉴얼로만 훈련받았다고 상상해보자. 심장외과 전문의가 우회로 수술 기법을 완벽히 익히는 대신 로켓 공학 방정식을 깊이 파고든다면 어떨까?
부정행위 조사관이라면? 몇 시간씩 미술사 강의를 듣느라 시간을 보내겠지.
단 하나의 범용 AI 모델로 모든 문제를 해결하려고 할 때 벌어지는 일이 바로 이와 같다.
적어도 내가 보기엔, 미래의 AI는 모든 분야를 지배할 하나의 거대한 모델이 아니다.
수천 개의 전문화된 모델들이 각각의 도메인에 맞춰 섬세하게 미세 조정(fine-tuning)되는 시대가 될 것이다. 바이오테크, 사이버 보안, 물류 등 다양한 분야에 특화된 AI 말이다.
우리는 한 사람이 최고의 의사이자 동시에 최고의 변호사, 최고의 엔지니어가 되기를 기대하지 않는다. 그렇다면 AI에는 왜 그런 기대를 해야 할까?
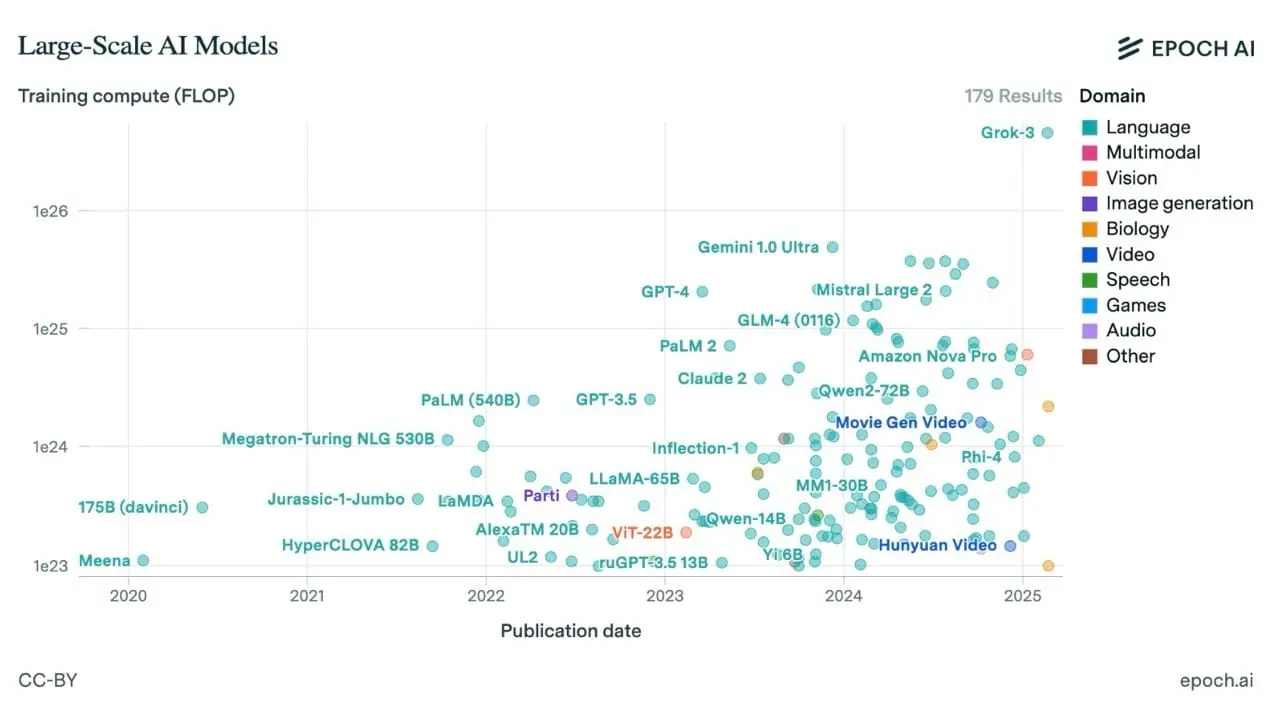
이미지 출처: Epoch AI
그동안 많은 연구소들은 더 큰 모델, 더 큰 데이터셋, 더 범용적인 인공지능을 만들어 규모(scale)를 키우는 데 집중해왔다. 논리는 간단했다. "충분히 많은 데이터를 학습하면 AI가 뭐든 할 수 있게 된다"는 것이다. 어느 정도는 효과가 있었다. 실제로 GPT-4, Claude, Gemini 같은 모델은 코드를 작성하고 논문을 요약하는 등 다양한 일을 수행할 수 있다. 하지만 현실을 냉정하게 보자면, 크기와 규모만으로 전문가 수준의 AI가 되는 것은 아니다.
최근 AI 모델의 스케일링 법칙에 따르면, 사전 훈련(pre-training)에 사용되는 컴퓨팅 자원을 늘리면 모델 성능이 향상되긴 하지만, 특정 전문 분야(domain-specific)의 작업에서는 오히려 수익 체감 현상(diminishing returns)이 나타나고 있다. 이제 시장은 광범위한 능력을 가진 범용 모델이 아니라, 특정 분야에서 속도와 정확도 면에서 최적화된 전문화된 시스템을 원하고 있다.
기업들이 원하는 AI는 느리지만 깊게 생각하는 모델이 아니라, 빠르고 정확하게 자신들의 비즈니스 요구사항에 최적화된 모델이다.
OpenLedger는 이와 같은 전문화된 AI의 미래에 큰 투자를 하고 있다.
OpenLedger → 전문화된 AI 모델
하지만 한 가지 큰 과제가 있다. 바로, 전문화된 AI 모델은 반드시 전문화된 데이터가 필요하다는 것이다.
법률 AI를 만들 때 위키피디아에서 수집한 데이터로 훈련시킨다면 유용하지 않을 것이다. 바이오테크 AI 역시 PubMed에서 단순히 스크랩한 정보만으로는 의료 혁신을 일으킬 수 없다. 최고 수준의 AI 모델은 실제 전문가들이 만들어낸 고품질의 도메인 특화 데이터를 반드시 필요로 한다. 그러나 이런 가치 있는 데이터를 실제로 만들어내는 과학자, 분석가, 엔지니어, 변호사와 같은 전문가들은 정작 자신들의 전문 지식이 AI 개발에 사용되는 데 대해 제대로 된 보상을 거의 받지 못하고 있다.
이러한 불완전한 시스템을 OpenLedger가 고치고자 한다.
상상해보자. 자신이 작성한 연구 논문이나 금융 모델이 전문화된 AI 모델을 훈련하거나 미세 조정하는 데 사용될 때마다 돈을 받을 수 있는 세상을 말이다.
데이터를 일괄 판매해서 받는 일회성 수익이 아니라, 그 데이터가 접근되거나 AI의 응답 생성에 활용될 때마다 지속적으로 수익이 생기는 구조다.
이것이 OpenLedger가 꿈꾸는 비전이다. 데이터 기여자들이 직접 보상을 받고, 자신들의 지식이 어떻게 활용되고 있는지 투명하게 확인할 수 있는 경제 생태계이다.
절차는 간단하다:
- 누구나 데이터를 제공할 수 있다.
- AI 모델이 그 데이터를 사용하여 성능을 높인다.
- 데이터 제공자는 데이터가 활용될 때마다 소액의 보상(micropayment)을 받는다.
이것은 AI가 만들어지고 지속되는 방식을 근본적으로 재구성한 것이다. OpenLedger는 OpenAI나 AWS와 같은 AI 거대 기업이나 인프라 제공업체와 경쟁하려고 하지 않는다.
그 대신 데이터, 컴퓨팅 자원, AI 모델이 투명성과 금전적 보상과 함께 원활히 상호작용할 수 있는 탈중앙화되고 허가가 필요 없는 프레임워크를 제공한다.
"Payable AI"
OpenLedger는 "Payable AI"라는 개념을 통해 위 문제를 해결한다.
그런데… 이 "Payable AI"라는 게 뭐지?
유튜브 이전만 해도 대부분의 사람들에게 비디오 콘텐츠 제작은 전망 없는 일이었다. 할리우드 같은 대형 제작사의 지원이 없다면, 수익을 창출할 방법은 없었다.
하지만 2005년 모든 것이 바뀌었다. 유튜브는 카메라와 인터넷만 있다면 누구나 전 세계 관객에게 접근할 수 있게 해줬다. 2006년에는 하루 1억 회 이상의 조회수를 기록하며, 사용자가 직접 만든 콘텐츠(User-Generated Content, UGC)의 엄청난 수요를 증명했다.
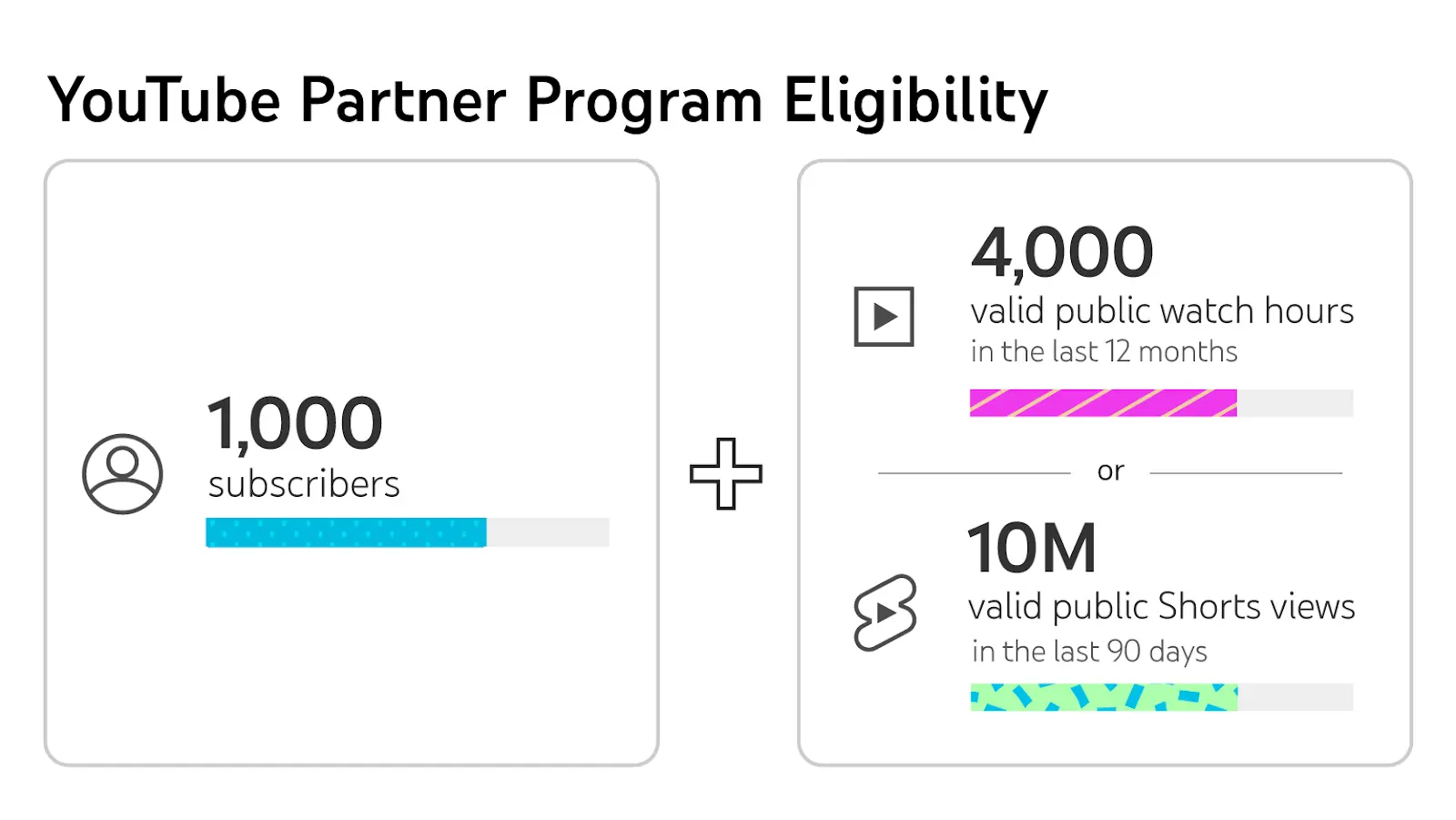
진정한 변화는 2007년 유튜브 파트너 프로그램이 시작되면서 찾아왔다. 콘텐츠 제작자들은 광고 수익에서 직접 수입을 얻을 수 있었고, 그 결과는 놀라웠다.
- 2023년 한 해 동안만 315억 달러의 광고 수익을 올렸다.
- 2021~2023년 사이에 제작자들에게 지급된 금액은 무려 700억 달러 이상이다.
- MrBeast는 2023년 한 해에만 8,200만 달러를 벌었다.
유튜브는 거대 미디어 기업뿐 아니라 개인들도 수익을 올릴 수 있는 크리에이터 경제를 구축했다.
이제 OpenLedger가 AI 데이터 분야에서 같은 일을 하고 있다. 이것을 데이터 분야에서 일어나는 "유튜브의 순간"이라고 생각하면 이해하기 쉽다.
비즈니스 관점에서 볼 때 유튜브와의 비교는 매우 적절하다:
- 유튜브: 제작자가 무료로 영상을 올리면 유튜브가 광고를 실행하고 수익을 제작자와 나눈다.
- OpenLedger: 데이터 기여자가 무료로 전문 데이터를 업로드하면, AI 앱이 데이터 사용료를 지불하고, 블록체인 상에서 수익을 데이터 제공자, 모델 제작자, 스테이커들과 나눈다.
현재 가치 있는 데이터셋(예: 전문 법률 문서, 고품질 코드 라이브러리, IoT 센서 데이터 등)을 보유한 사람들의 선택지는 매우 제한적이다: 데이터를 일회성으로 판매하거나 아니면 그냥 비공개로 유지하는 정도다. OpenLedger는 여기에 세 번째 옵션을 제시한다. 즉, AI 모델이 데이터를 사용할 때마다 지속적인 수익을 얻을 수 있게 하는 것이다.
이는 다음과 같은 선순환(Flywheel) 효과를 만들어낸다:
- 더욱 가치 있는 데이터가 시스템에 들어온다.
- AI 모델이 더 전문화되고 유용해진다.
- 더 많은 수요가 발생하여 지급금이 증가한다.
- 더 많은 기여자들이 참여해 생태계가 더욱 강화된다.
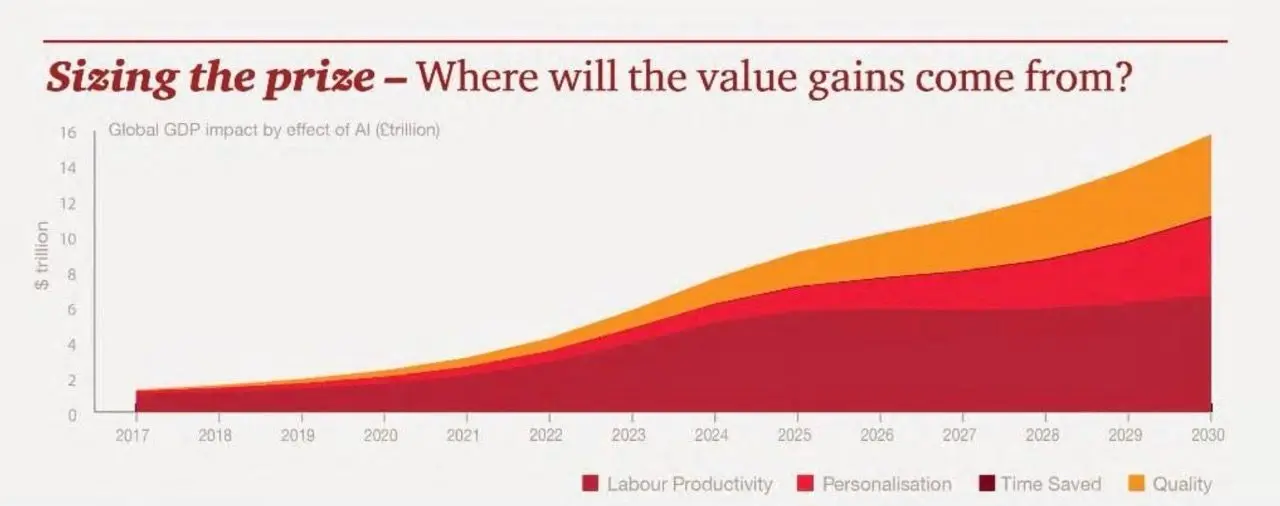
이 기회의 규모는 막대하다. PwC의 예측에 따르면 AI는 2030년까지 글로벌 경제에 최소 15.7조 달러 이상을 기여할 것이며, 연평균 성장률은 28%에 이를 것으로 보인다. 하지만 더 나은 AI 모델과 앱을 만들 때 가장 큰 병목 현상은 고품질의 라벨링된 데이터를 확보하는 것이다. OpenAI와 같은 회사들이 좋은 데이터셋 확보에 수십억 달러를 투자하는 이유도 바로 데이터의 품질이 AI 모델의 성능을 결정짓기 때문이다.
데이터 기여(Attribution) 문제 해결하기
"Payable AI"가 제대로 작동하기 위해, OpenLedger는 데이터 기여(attribution) 문제를 해결해야 한다.
그것은 바로 AI가 내놓는 결과에 실제로 어떤 데이터가 영향을 주었는지를 확인하는 것이다. 특정 데이터가 모델 성능 향상에 결정적일 수 있지만, 어떤 데이터는 거의 아무 영향이 없을 수도 있다. 그런데 실제로 이런 영향력을 정확히 추적할 수 있을까?
솔직히 나는 회의적이었다.
AI에서의 기여 문제(특히 대규모 언어 모델, LLM의 경우)는 머신 러닝 분야에서 가장 어려운 과제 중 하나다. 이런 모델들은 수십억 개의 파라미터로 수조 개의 토큰을 처리하기 때문에 어떤 특정 데이터가 결과에 영향을 줬는지 정확히 파악하는 것이 거의 불가능하다.
수년간 연구자들은 데이터의 영향력을 측정하려고 노력해왔다. 가장 단순한 방법은 데이터를 하나 제거한 뒤 모델을 다시 훈련시키고 결과를 비교하는 것이다.
하지만 GPT-4 같은 모델을 다시 훈련시키려면 최초 훈련에 사용한 컴퓨팅 비용의 10~100배가 드는데, 이는 적어도 100억 달러 이상의 비용이 드는 엄청난 일이다. 현실성이 전혀 없는 접근법이다.
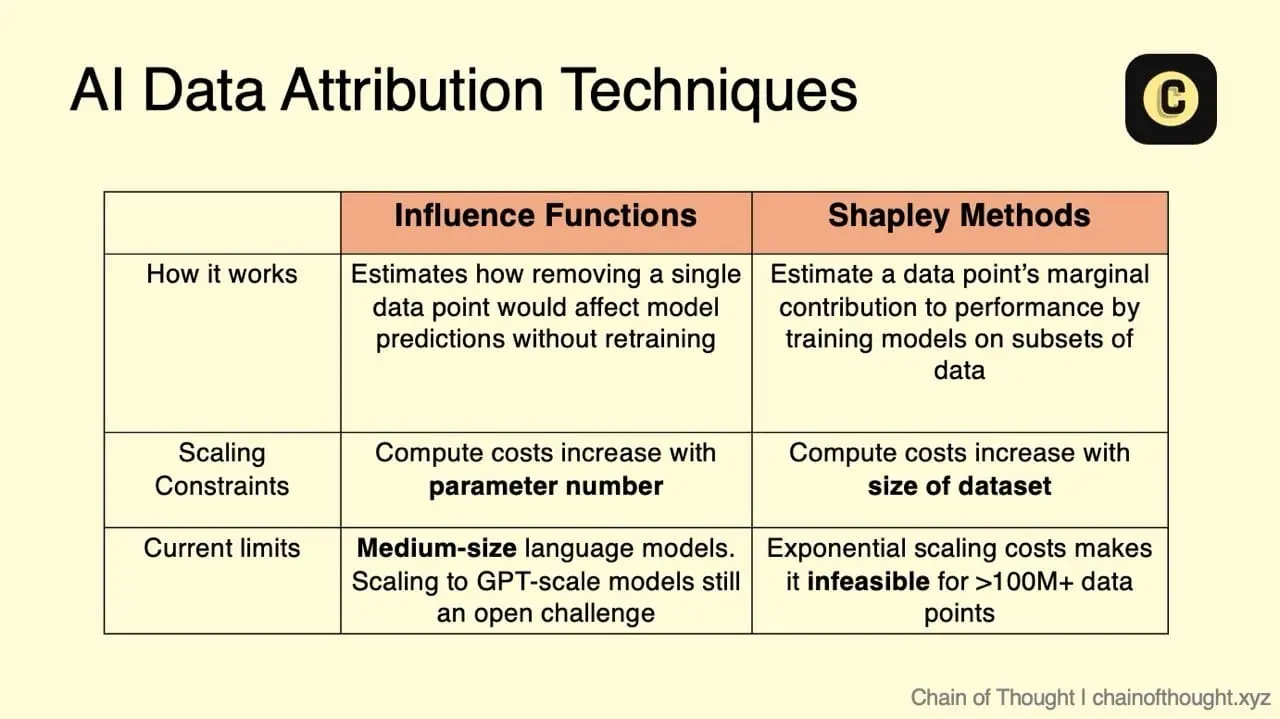
대신 연구자들은 더 효율적인 추정 방법을 개발해왔다:
영향 함수(Influence Functions)는 데이터 하나를 제거했을 때의 모델 성능 변화를 수학적으로 근사하여 다시 훈련하지 않고 영향력을 추정한다. 이는 점점 개선되고 있지만, 대규모 모델에서의 적용은 여전히 어렵다.
최근 LoGra는 그래디언트 투영 방식을 통해 계산량을 6,500배 줄이고 GPU 메모리 사용량을 5배 감소시켰다. 덕분에 LLaMA-3 8B와 같은 중형 모델에서는 영향력 추적이 가능해졌지만, 파라미터가 100B 이상인 대규모 모델에서는 여전히 실현하기 어렵다.
또 다른 방법으로 게임이론에서 차용한 셰이플리 값(Shapley Values)이 있는데, 이는 데이터의 한계 기여를 계산하기 위해 수많은 데이터 조합으로 모델을 훈련해야 하므로 엄청난 비용이 소요된다.
무작위의 이질적인 웹 데이터로 훈련된 거대 AI 모델에서 데이터의 영향력을 정확히 추적하는 것은 꿈 같은 얘기다.
하지만 잘 정제된 도메인 특화 데이터로 훈련된 전문화된 AI 모델에서는 데이터 기여 추적이 갑자기 훨씬 더 실현 가능해진다. 현재 AI 분야의 흐름이 LoRA 방식으로 튜닝된 도메인 특화 모델로 옮겨가고 있기 때문이다.
- 의학 문서로 훈련된 의료 LLM이나 운전 영상 데이터로 훈련된 자율주행 모델의 경우, 데이터 규모가 수십억 개가 아닌 수천 혹은 수백만 개 수준에 불과하다. 바로 이 점 때문에 전수조사식(brute-force) 기여 추적 방식이 훨씬 현실적으로 가능해진다.
- 범위가 좁을수록 기여도의 명확성(attribution clarity)도 높아진다. 예컨대 의료 Q&A 모델은 특정 교과서 단락 하나만을 참고해 답변을 내놓을 수도 있다. 그러나 범용 모델에서는 동일한 답변이 여러 출처에서 혼합된 결과이기 때문에 기여도 추적이 어렵다. 반면, 전문화된 모델에서는 기여를 추적하는 데 필요한 신호대잡음비(signal-to-noise ratio)가 훨씬 높아진다.

(https://arxiv.org/pdf/2310.00902)
OpenLedger 프로토콜의 영감이 된 핵심 논문(key paper)에서는 기존 방식보다 데이터의 영향력을 훨씬 효율적으로 추정할 수 있는 방법을 제안했다. 이 획기적인 접근법의 핵심은 바로 LoRA 기반으로 튜닝된 모델(LoRA-tuned models)에 최적화되어 있다는 것이다. LoRA 기반 모델이란 전체 AI 모델을 다시 처음부터 훈련하지 않고, 작고 집중적인 업데이트만으로 미세 조정(fine-tune)을 수행하는 AI 어댑터(adapter)를 의미한다.
물론, 그렇다고 해서 데이터 기여(attribution)가 쉬워졌다는 뜻은 아니다. 심지어 전문화된 모델에서도 데이터의 영향력을 정확히 추적하는 일은 상당한 노력을 요구한다. 그러나 이제 최초로 기술적으로 실현 가능한 단계에 이르렀다는 점에서 의미가 크다.
데이터의 영향력을 추적할 수 있다면, 데이터 기여자들에게 공정한 보상을 제공할 수 있다. 이것이 바로 ‘Payable AI(보상 가능한 AI)’를 현실에서 구현할 수 있게 만드는 핵심이다.
기여 증명(Proof-of-Attribution)
OpenLedger만의 핵심 기술은 Proof of Attribution (PoA, 기여 증명)이다. 간단히 말해, PoA는 다음 네 가지 핵심 역할을 수행한다:
- 데이터가 AI 모델에 어떻게 기여하고, 활용되는지를 추적한다.
- 데이터의 유용성을 블록체인 상에서(on-chain) 검증한다.
- 특정 데이터를 사용하여 AI 모델이 추론을 할 때마다 데이터 제공자에게 비례적으로 보상한다.
- 어떻게 보상이 이뤄졌고, 결정이 내려졌는지를 투명하고 검증 가능하게 한다.
AI 모델이 사용될 때마다, 네트워크는 어떤 데이터 포인트가 결과에 기여했는지 다시 추적해 블록체인 상에 기록한다. 이 "영향력 매핑(influence mapping)"이 100% 완벽하진 않겠지만, 데이터셋 각각의 중요도를 파악하고 공정하게 보상을 분배할 수 있을 만큼 충분히 정확하다.
이러한 방식으로 OpenLedger는 다음 세 주체에게 실시간으로 마이크로페이먼트(micropayment)를 제공한다:
- 모델 제작자(Model creator) – 전문화된 AI 모델을 개발하고 미세 조정한 대가로 보상 받는다.
- 데이터 기여자(Data contributor) – 가치 있는 훈련 데이터를 제공한 대가로 보상 받는다.
- 유동성 공급자(Liquidity provider) – 모델 운영을 지원하기 위해 토큰을 스테이킹한 대가로 보상 받는다.
이 구조가 바로 "Payable AI" 개념의 핵심이다. 당신이 데이터셋을 제공하면, 데이터가 살아있는 AI 모델에서 사용되는 한 계속해서 보상을 받을 수 있다.
Hugging Face vs. OpenLedger: 사라진 인센티브 레이어
Hugging Face와 비교해보면 흥미로운 차이점이 드러난다. Hugging Face는 최근 펀딩 라운드에서 기업 가치가 45억 달러로 평가되었고, 2023년 매출은 7천만 달러에 달했다.
Hugging Face는 연구자들이 더 쉽게 모델을 공유하고 미세 조정할 수 있게 만들어 오픈소스 AI를 혁신했다. 하지만 데이터 기여(attribution)와 보상(compensation) 문제를 해결하지는 못했다. 즉, AI에 데이터를 기여하는 사람들은 여전히 무료로 자신의 데이터를 제공한다.
반면, OpenLedger는 Hugging Face의 오픈 액세스 철학을 기반으로 하면서도 금융적 인센티브와 책임성을 추가했다. Hugging Face가 탐색과 실험에 적합한 플랫폼이라면, OpenLedger는 데이터 기여자, 모델 개발자, 기업 등 실제 이해관계자들이 경제적 인센티브로 결합된 현실적인 AI 경제 생태계를 목표로 한다.
물론 PoA에도 한계가 있다. 소규모의 도메인 특화 모델에서는 잘 작동하지만, 대규모의 일반적인 LLM에서는 여전히 현실성이 부족하다. 파라미터가 100B 이상 규모의 모델에서 기여를 정확히 측정하는 것은 아직 해결되지 않은 과제다. LoRA 기술의 사용 증가로 미세 조정 비용은 줄어들었지만, 기여 문제를 해결하지는 못했다. 그저 문제를 축소했을 뿐이다.
OpenLedger가 실제로 대규모 모델에서도 기여 문제를 효과적으로 해결할 수 있을지는 아직 지켜봐야 한다. 하지만 만약 이를 성공적으로 해결한다면, AI의 경제적 구조 자체가 크게 달라질 수 있다.
OpenLedger의 내부 구조: 어떻게 작동하는가
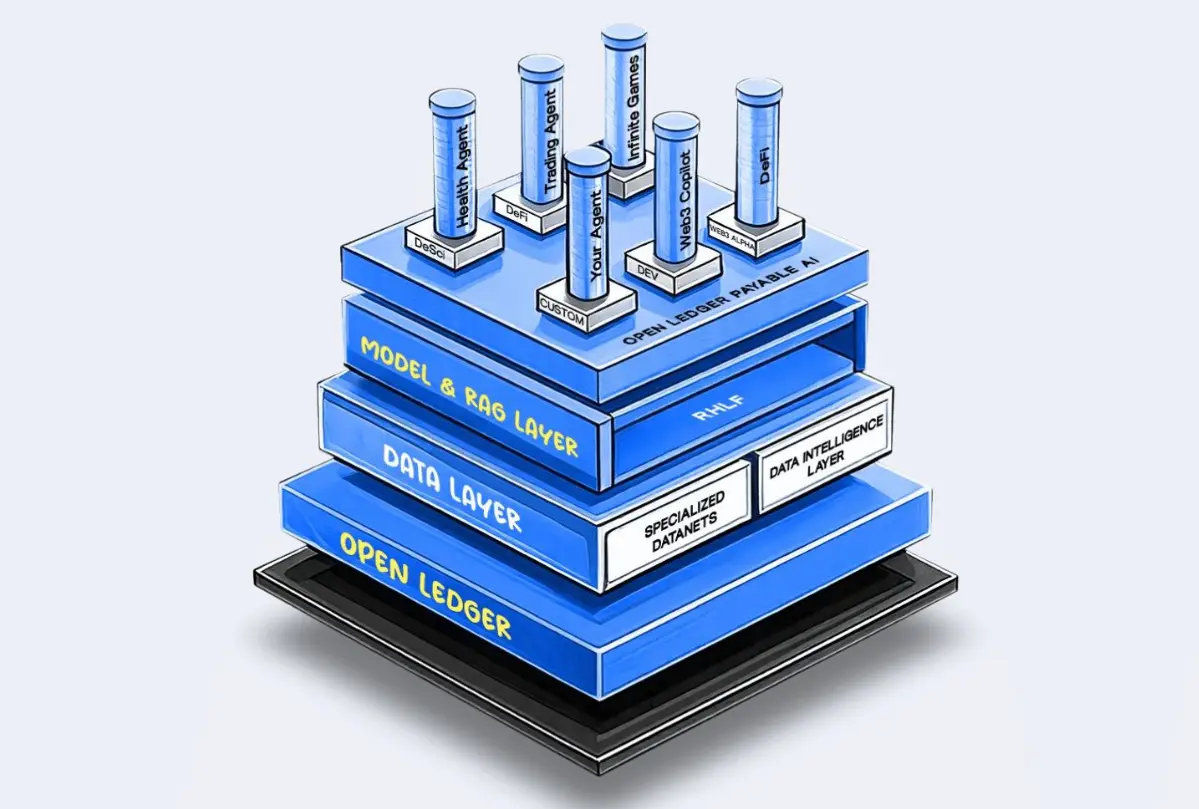
기여자들에게 보상하는 시스템이 훌륭하다는 점은 명확해졌다. 이제 시스템이 실제로 어떻게 작동하는지 살펴보자.
OpenLedger 플랫폼의 내부 구조는 크게 세 가지 레이어로 구성되어 있다:
- 데이터 레이어(Data Layer) – 도메인 특화 정보를 저장하는 전문 데이터 네트워크(DataNets)를 운영한다.
- 모델 & RAG 레이어(Model & RAG Layer) – 도메인 특화된 언어 모델(SLMs)과 검색 기반 생성(Retrieval-Augmented Generation, RAG) 시스템을 갖추고 있으며, 이는 추론 시 실시간으로 데이터를 불러와 활용한다.
- 애플리케이션 레이어(App Layer) – 최종 소비자가 사용하는 실제 AI 애플리케이션(DeFi 에이전트, Web3 AI 어시스턴트 등)이 있는 레이어다.
여기서 블록체인이 하는 역할은 무엇인가? 블록체인은 허가가 필요 없는 협업을 가능하게 하고, 각 주체 간의 인센티브를 조정하며, 소액 결제를 실제로 가능하게 만드는 핵심적 역할을 한다.
데이터넷(DataNets)
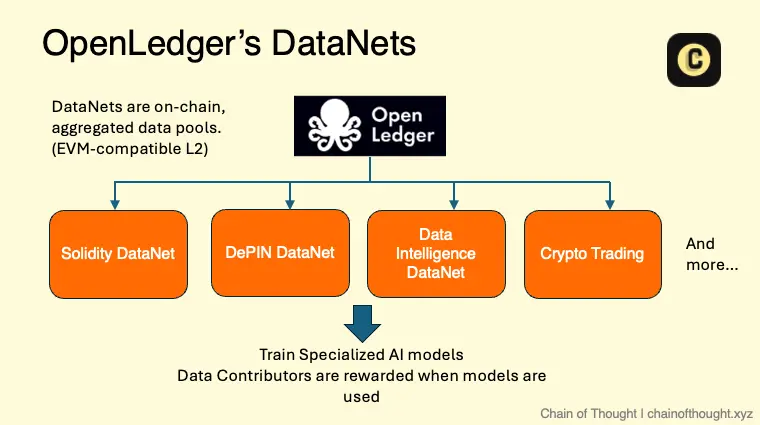
개인이 각자의 데이터를 개별적으로 제공하는 것도 물론 가능하지만, 진정한 힘은 전문화된 데이터셋을 집합적으로 구축하는 것에서 나온다.
OpenLedger 시스템의 핵심에는 데이터넷(DataNets)이라는 탈중앙화되고 검증 가능한 데이터 저장소가 있다. 데이터넷은 AI 모델의 훈련과 성능 개선에 필요한 고품질의 도메인 특화 데이터를 제공하는 역할을 한다.
기술적으로 설명하자면, OpenLedger에서 데이터넷이란 특정 도메인의 데이터를 어떻게 수집할지를 규정하는 일종의 스마트 컨트랙트(EVM 호환 가능한 레이어2 위에서 작동하는)라고 할 수 있다. 여기에는 Solidity 코드 데이터, 법률 데이터, IoT 센서 데이터 등 다양한 형태가 포함될 수 있다.
데이터넷은 일종의 데이터 DAO와 비슷한 방식으로 작동한다. 기여자들이 도메인 특화 데이터를 제출하면, 각 데이터넷은 어떤 데이터가 수용될 수 있는지, 데이터 품질 검증을 어떻게 수행할지 등에 관한 명확한 규칙을 가지고 있다. 검증이 완료된 데이터는 분산 저장 방식으로 보관된다. 데이터의 해시(hash)는 온체인(on-chain)에 기록되며, 원본 데이터(raw data)는 오프체인(off-chain)에 저장되어 고정(pinned)되는 구조이다.
데이터 무결성을 유지하기 위해 검증자(validators)는 토큰을 스테이킹(staking)해야 한다. 이를 통해 데이터의 신뢰성과 유효성을 유지하는 인센티브 구조를 형성한다. 모든 데이터 사용은 블록체인에 기록되고 기여자가 지속적으로 보상을 받게 된다.
AI 분야에서는 데이터의 양보다 질이 중요하다. DataNets는 더 많은 데이터가 아니라 더 나은 데이터를 기반으로 인텔리전스를 구축하는 것을 보장한다.
솔리디티 데이터넷(The Solidity Datanet0
당신이 스마트 컨트랙트를 작성하고 디버깅하기 위해 AI를 사용하는 Solidity 개발자라고 하자. 하지만 일반적인 AI 모델은 신뢰하기 어렵다. 범용 모델들은 지저분하고 구식의 데이터—불완전한 GitHub 코드 조각들, 명확하지 않은 베스트 프랙티스, 좋지 않은 조언으로 가득 찬 포럼 게시물 등으로 훈련된다. 이들은 종종 잘못된 코드를 생성하고, 보안 결함을 놓치며, 가스를 낭비한다.
그런데 만약 AI가 실제로 Solidity를 "이해"할 수 있고, 프로덕션 배포 전에 보안 감사를 하고, 가스를 최적화하며, 취약점을 잡아낼 수 있다면 어떨까?
이것이 바로 이더리움 개발자 커뮤니티가 구축하고 있는 "Solidity DataNet"의 비전이다. 검증된 코드 조각, 보안 감사 결과, 전문가 Q&A 등을 블록체인 상에서 관리되는 저장소에 큐레이션하는 것이다. 일반적인 모델이 아니라, 가스 최적화와 보안 감사를 기반으로 훈련된 전문화된 AI를 통해 스마트 컨트랙트 개발을 돕는다.
작동 방식은 다음과 같다:
개발자들이 높은 신뢰도를 가진 검증된 데이터를 Solidity 지식 데이터넷에 모은다. 데이터를 기여하기 위해 토큰을 스테이킹하고, 검증자는 데이터의 정확성을 확보한다. 데이터셋이 점차 커지면 이것을 기반으로 오픈소스 LLM(Llama 같은)을 미세 조정한다.
그 결과 이더리움의 실행 환경을 잘 이해하는 Solidity 네이티브 AI 어시스턴트가 만들어진다. 개발자나 기업들이 이를 사용하기 위해 비용을 지불할 때마다, 수익은 모델 제작자, 데이터 기여자, 그리고 모델 런칭을 지원하기 위해 토큰을 잠근 LP 스테이커들에게 돌아간다.
이러한 방식의 데이터넷은 여러 도메인에서 계속해서 생겨나고 있다.
데이터 인텔리전스 모델(Data intelligence model)
구글 딥마인드(Google DeepMind) 출신 연구자인 크리슈나 스리니바산(Krishna Srinivasan)은 Data Bootstrap이라는 실시간, 지속적으로 업데이트되는 데이터넷을 이끌고 있다. 이는 차세대 Common Crawl과 유사하다.
이 방식은 웹을 정적인 배치(batch) 방식으로 스크레이핑하는 것이 아니라, 커뮤니티가 운영하는 노드들을 활용해 병렬적으로 웹 데이터를 수집한다. DataNet은 최신의 맥락 정보로 AI 에이전트를 지속적으로 업데이트하여 보다 날카롭고 정확한 응답을 가능하게 한다.
DePIN 데이터넷(DePIN DataNet)
OpenLedger 팀은 다양한 DePIN(탈중앙화 물리적 인프라 네트워크) 프로젝트와 협력하여 실시간 공유 데이터 레이어를 구축하고 있다. 이는 날씨 예측 모델, 탈중앙화 매핑 시스템, IoT 네트워크 등 다양한 분야에서 활용 가능하다.
이것이 왜 중요할까? 일부 애플리케이션은 데이터가 지속적으로 업데이트되지 않으면 그 가치가 급격히 떨어지기 때문이다.
- 날씨 예측의 예시: 도시 전역에 설치된 수천 개의 작은 센서들이 특화된 날씨 모델에 데이터를 공급하면, 초지역적(hyper-local)으로 분 단위까지 세부적인 날씨 예측이 가능해진다.
- 실시간 매핑의 예시: 드론, 자동차, IoT 장비 등이 지리 공간 데이터를 수집하면, 이 데이터는 특화된 지도 모델에 입력된다. 모델은 실시간으로 업데이트되며, 데이터 소유자들에게 지속적인 보상이 돌아간다.
대규모 기여자 네트워크가 지속적으로 데이터를 업데이트하면, 전문화된 모델은 항상 최신 상태를 유지할 수 있다. 따라서 모든 참여자는 데이터의 최신성과 품질을 유지할 강력한 인센티브를 얻게 된다.
Web3 트레이딩 데이터넷(Web3 Trading DataNet)
당신이 DeFi에 깊숙이 관여하고 있으며 더 나은 트레이딩 시그널을 얻고 싶다고 가정해보자. 다음과 같은 데이터를 모아 Web3 트레이딩 데이터넷을 구축할 수 있다:
- 온체인 히스토리컬 데이터
- 오프체인 센티먼트 데이터 (트위터, 텔레그램 피드 등)
- 지갑 분석 데이터 (고래 및 스마트머니의 움직임)
- 거시경제 뉴스 및 시장 트렌드
이후 토큰을 스테이킹하여 기여자들을 유치하고, 고급 트레이딩 인텔리전스를 위한 모델을 파인 튜닝(fine-tuning)한다. 그러면 당신이나 혹은 다른 누군가가 그 모델을 자율적인 거래 에이전트로 패키징할 수 있다. 이 에이전트는 하루에 수천 건의 거래를 실행하며, 각 거래가 일어날 때마다 데이터 제공자, 모델 스테이커, 에이전트 운영자에게 소액의 보상이 돌아가게 된다.
일종의 "서비스형 알파(Alpha-as-a-Service)"인 셈이다.
헬스케어 데이터넷(Healthcare DataNet)
병원들은 안전한 하드웨어 기반 보안 구역(TEE, Trusted Execution Environment) 내에서 프라이빗 데이터넷을 구축하여 프라이버시를 철저히 보호하면서도 의료 진단 AI를 위한 데이터 접근성을 보장할 수 있다. 이러한 데이터셋은 익명화된 환자 기록, 임상 시험 결과, 실제 의료 현장의 인사이트를 결합하여, 지속적으로 발전하는 의료 인공지능의 지식 기반을 형성한다.
이렇게 구축된 데이터로 미세 조정과 엄격한 검증을 마친 AI 모델은 소규모 클리닉, 원격 의료 플랫폼, 연구 기관 등에 배포되어 고급 의료 진단 기술을 보다 폭넓게 활용할 수 있도록 지원한다. 특히, AI 모델의 모든 사용 쿼리는 데이터 소유자에게 마이크로페이먼트(micropayment)를 지급하게 되어 있어 데이터 제공자들이 지속적으로 보상을 받게 되며, 동시에 의료 AI 기술이 독점적이고 폐쇄적인 시스템에 갇히지 않고, 공인된 기관들 사이에서 개방적으로 활용될 수 있도록 한다.
모델 및 RAG 레이어: OpenLedger 테스트넷
OpenLedger의 테스트넷은 이미 가동 중이며, 두 가지 제품을 통해 사용자가 모델과 RAG(Retrieval-Augmented Generation, 검색 기반 생성) 레이어가 어떻게 동작하는지 직접 체험해볼 수 있다.
제품 #1: Model Factory
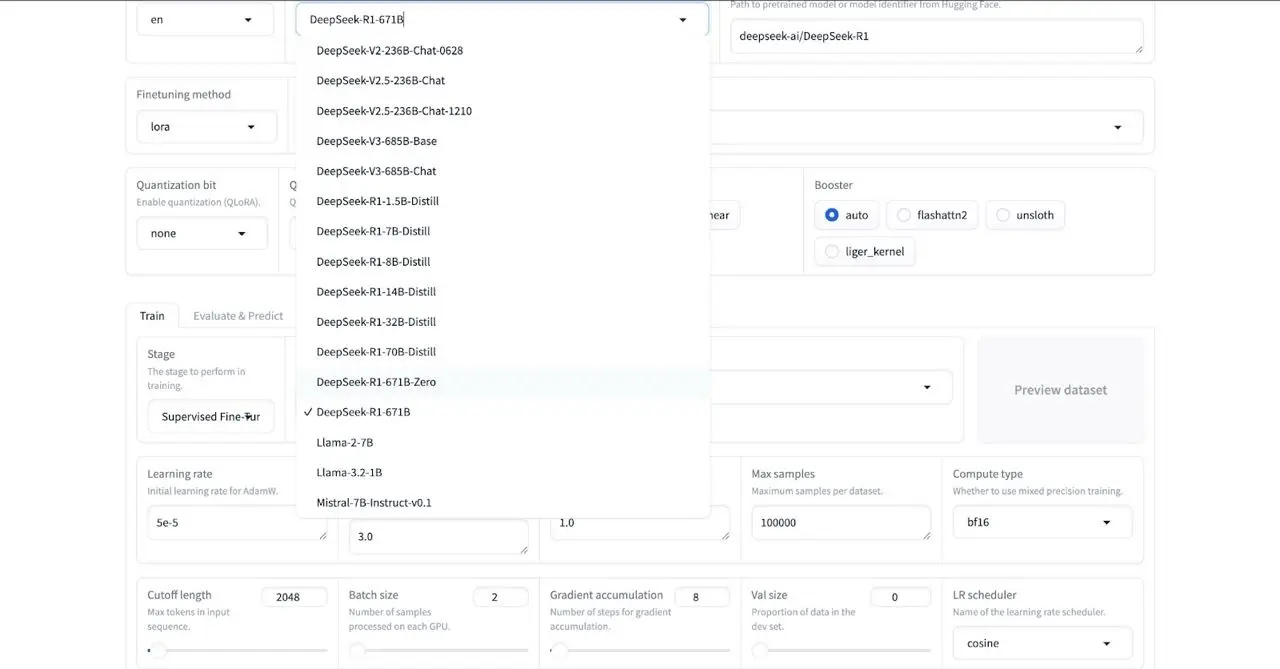
대형 언어 모델(LLM)을 미세 조정(fine-tuning)하는 일은 일반적으로 매우 복잡하며, 명령줄 도구(command-line tools), API 연동, 깊이 있는 머신러닝(ML) 전문 지식을 요구한다. 개발자가 아닌 일반 사용자 입장에서는 이러한 복잡한 과정에서 쉽게 혼란을 겪거나 좌절감을 느끼기 마련이다.
ModelFactory는 이 문제를 완벽한 GUI 기반 플랫폼으로 해결한다. 사용자는 코드 한 줄 작성하지 않고도 손쉽게 AI 모델을 미세 조정할 수 있다.
데이터 파이프라인을 구축하느라 애쓸 필요 없이, OpenLedger를 통해 데이터셋을 요청하고 데이터 제공자의 승인을 받으면 이를 곧바로 ModelFactory 인터페이스에 연동할 수 있다. 그런 다음 원하는 모델(LLaMA, Mistral, DeepSeek 등)을 선택하고, 직관적인 대시보드를 통해 하이퍼파라미터를 설정한 후 LoRA 또는 QLoRA 방식으로 미세 조정을 수행하면 된다. 이 모든 과정을 터미널이나 명령줄 없이 쉽게 완료할 수 있다.
실시간 훈련 분석 기능을 통해 즉각적인 피드백을 받을 수 있고, 미세 조정된 모델은 내장된 채팅 인터페이스를 통해 즉시 테스트하고, OpenLedger 생태계 내부에서 공유할 수 있다.
ModelFactory에서 특히 흥미로운 기능은 RAG 기여(attribution) 기능이다. AI가 생성한 응답이 정확히 어떤 데이터셋에서 비롯되었는지를 시각적으로 확인할 수 있다. 매우 매력적인 기능이다.
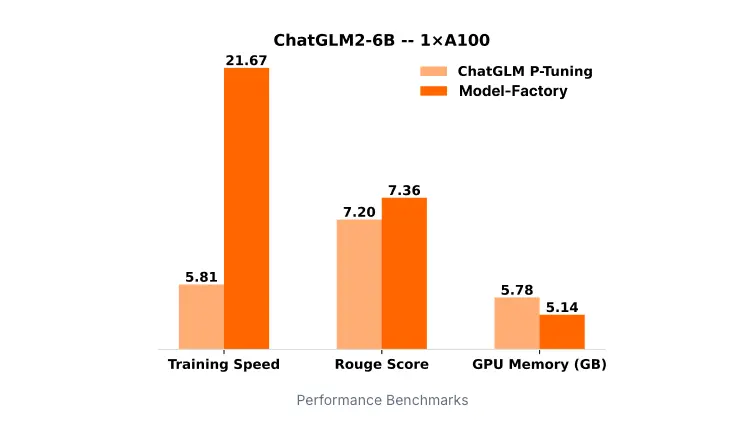
출처: OpenLedger
ModelFactory의 LoRA 튜닝은 기존의 전통적인 방법(P-Tuning 등)에 비해 훨씬 빠르고 효율적이다. 실제로 모델 훈련 속도가 최대 3.7배 빠르며, 이는 원하는 결과를 더 빠르게 얻을 수 있다는 뜻이다.
또한 텍스트 생성과 같은 작업에서도 정확도를 향상시킨다. Rouge 점수(생성된 텍스트와 인간이 쓴 글의 유사성을 평가하는 지표) 기준으로도 더 나은 성능을 보인다.
간단히 말해, 더 빠른 훈련과 더 좋은 결과를 동시에 얻을 수 있다.
제품 #2: Open LoRA
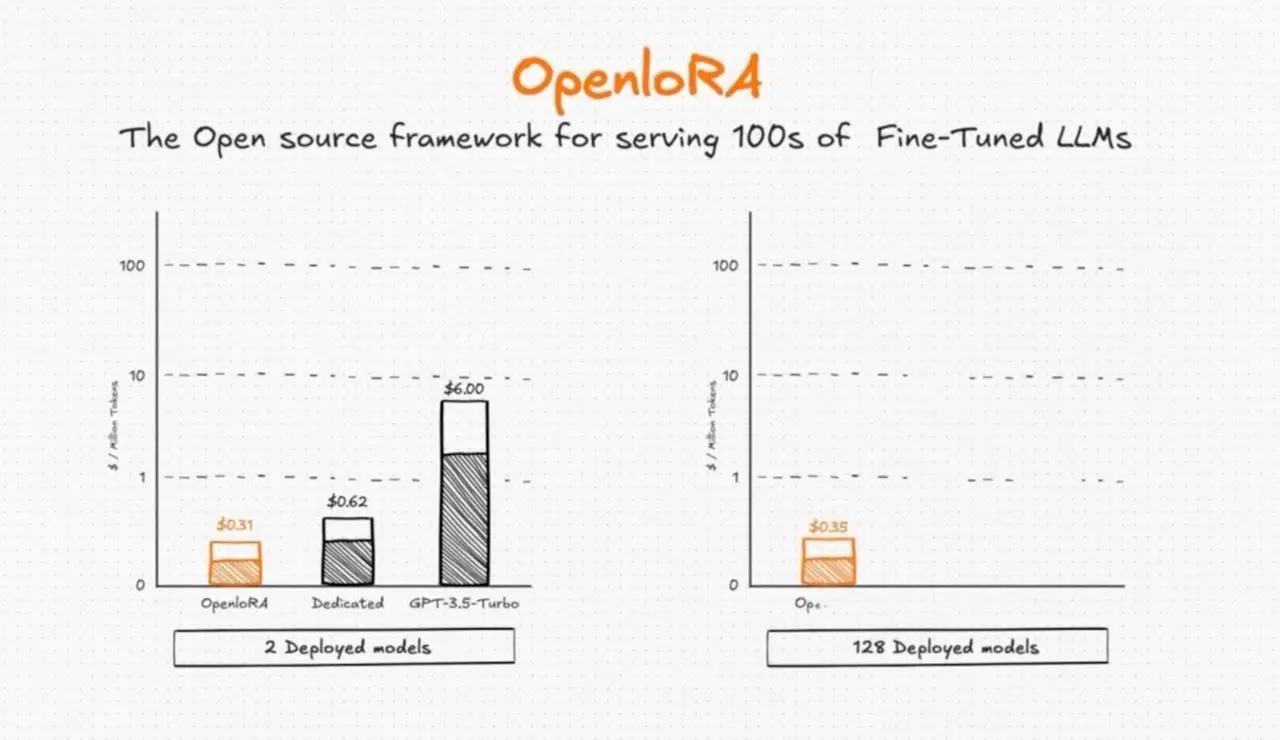
OpenLoRA는 개발자들이 모델마다 별도의 GPU를 사용하는 대신, 단 하나의 GPU에서 수천 개의 모델을 동시에 실행할 수 있는 프레임워크이다. 이를 통해 비용을 획기적으로 절감하고 유연성을 극대화한다.
낮은 지연(latency)과 높은 처리량(throughput)을 목표로 설계된 OpenLoRA는 한 대의 GPU로 100~1000개 이상의 LoRA(Low-Rank Adaptation, 저랭크 적응) 모델을 불필요한 메모리 낭비 없이 동시에 처리할 수 있다.
모든 미세 조정된 모델을 미리 로드하는 대신, 필요한 어댑터(adapter)를 실시간으로 불러와 병합한다. 기본 모델(예: Llama 3 또는 Mistral)은 메모리에 유지되고, OpenLoRA는 요청된 미세 조정 어댑터만을 불러옴으로써 자원 사용을 최소화한다. 또한 FlashAttention, PagedAttention, 양자화(quantization) 등의 최적화 기법을 통해 성능을 극대화하고, 실시간 토큰 스트리밍을 통해 응답 시간을 크게 단축한다.
그 결과, 모델 전환 시간은 100ms 이하로 빨라지고, 추론(inference) 속도는 획기적으로 빨라지며, 운영 비용은 대폭 감소한다.
이는 대규모 미세 조정 AI 모델을 합리적인 비용으로 실용화하는 큰 도약이다. OpenLoRA를 통해 수많은 미세 조정 AI 모델이 효율적으로 GPU 인프라를 공유하게 되며, AI 에이전트는 실시간으로 다양한 전문화된 모델 간을 유연하게 전환할 수 있게 된다.
결국, 개인화된 AI를 대규모로 제공할 수 있게 해주며, 동일한 하드웨어에서도 다양한 사용자와 작업에 따라 모델을 유연하게 전환할 수 있는 길을 열어준다.
OpenLedger 로드맵
OpenLedger의 테스트넷(testnet)은 단순히 시험 운영 이상의 의미를 가진다. 단계적 접근을 통해 메인넷(mainnet)에서의 비허가형 모델 구축(permissionless model-building)을 위한 기반을 마련하고 있다.
1단계: 테스트넷 출시 (2024년 12월)
테스트넷은 다음과 같은 요소들로 기반을 마련했다:
- 데이터 인텔리전스 레이어(Data Intelligence Layer): 인터넷 데이터를 실시간으로 수집, 검증 및 처리하는 파이프라인을 구축했다.
- 100만 개 이상의 노드 다운로드: 현재까지 노드 채택률은 매우 높은 편이다. Android, Windows, Linux, 브라우저 확장 프로그램 등을 통해 전 세계 150개국 이상의 지역에서 노드가 운영되고 있다. 노드 운영자들은 Grass와 유사한 방식으로 인터넷 데이터 스크레이핑(scraping)에 필요한 대역폭과 저장공간을 제공한다.
이 과정에서 포인트 시스템을 통한 인센티브가 제공되며, 이는 추후 에어드랍(airdrop)의 혜택으로 이어질 수 있다.
2단계: 데이터셋 확장 (2025년 1분기) → 현재 진행 단계
기본적인 인프라가 갖춰진 이후, 다음 단계는 데이터 자체의 품질을 높이는 것이다.
현재 커뮤니티는 OpenLedger의 데이터셋을 테스트하고, 검증하며, 지속적으로 개선하고 있다. 동시에 초기 개발자들은 전문화된 데이터넷(DataNets)을 구축하고 있으며, 메인넷 출시 전까지 모델 훈련과 검증 실험을 진행 중이다.

또 하나 주목해야 할 점은 바로 "골든 데이터셋(Golden Dataset)"의 준비다.
골든 데이터셋이 무엇일까?
골든 데이터셋은 고품질의 구조화되고 잘 선별된 데이터셋으로, 커뮤니티의 적극적인 참여로 정제된다. 도메인 특화 AI의 기반이 되는 데이터로 기획되었다. 무작위로 방대한 양의 미가공 인터넷 데이터를 수집하는 Common Crawl과 달리, 골든 데이터셋은 신중하게 선택되고, 정제되며, AI 훈련을 위해 최적화된다.
골든 데이터셋이 성공적으로 구축될 경우, 도메인 특화 AI 모델 구축의 장벽을 낮추고, 고품질의 허가형 데이터(permissioned data)에 대한 새로운 표준을 마련하여 경쟁 우위를 확보하게 될 것이다.
3단계: 메인넷 및 토큰 출시 (2025년 2분기)
OpenLedger는 2025년 2분기(Q2)까지 테스트넷에서 메인넷으로 전환하여 네트워크의 모든 기능을 활성화할 계획이다:
- 비허가형 AI 모델 구축(Permissionless AI Model-Building): 누구나 토큰을 스테이킹(staking)해 전문 언어 모델(Specialized Language Models, SLMs)을 미세 조정하거나 배포할 수 있게 된다.
- 토큰 생성 이벤트(Token Generation Event, TGE): 2025년 2분기 초반으로 예정되어 있으며, 이때 생성된 네이티브 토큰은 스테이킹, 거버넌스, 데이터 기여, 보상 등 다양한 용도로 활용된다.
- 기업 및 생태계 확장(Enterprise & Ecosystem Growth): 전문화된 데이터넷을 확대하고, 기여 증명(Proof of Attribution, PoA)을 정교화하며, 대기업 및 데이터 큐레이션 파트너를 생태계에 합류시킨다.
메인넷이 출시되는 시점에는 OpenLedger가 자체적으로 지속 가능한 AI 경제 생태계를 구축하기 위한 모든 기반이 완성된다. 데이터 제공자, 모델 제작자, 기업들이 서로 협력하여 차세대 도메인 특화 AI를 만들 수 있는 환경이 마련되는 것이다.
펀딩 현황
현재까지 OpenLedger는 총 1,050만 달러의 투자를 유치했다. 2024년 7월에 폴리체인 캐피탈(Polychain Capital)과 보더리스 캐피탈(Borderless Capital)이 주도한 시드 라운드(seed round)에서 800만 달러를 유치했으며, 이외에도 Finality Capital, Hash3, HashKey Capital, STIX, TRGC, Mask Network, MH Ventures, WAGMI Ventures 등이 투자에 참여했다.
해당 라운드에는 크립토 및 AI 분야의 핵심 인사들도 참여했는데, 대표적으로는 발라지 스리니바산(Balaji Srinivasan, 전 Coinbase CTO), 산딥 네일왈(Sandeep Nailwal, 폴리곤 창업자), 스리람 카난(Sreeram Kannan), 비야스 크리슈난(Vyas Krishnan, EigenLabs), 스콧 무어(Scott Moore, Gitcoin) 등이 있다.
최근 몇 개월 사이 Echo와 일부 벤처캐피탈로부터 추가로 250만 달러를 확보했다.
OPN 토크노믹스
OpenLedger 토큰(OPN)의 세부적인 토큰 설계는 아직 완전히 공개되지 않았으나, 핵심 메커니즘은 다음과 같은 방식으로 구성된다.
토큰의 가치는 체계적인 라이프사이클을 통해 흐른다. 개발자는 OPN 토큰을 스테이킹하여 모델을 런칭하고, 유동성 공급자(LP)가 이를 지원한다. 가장 우수한 성과를 내는 모델은 프로토콜 재정(treasury)에서 기여 보상(attribution reward)을 얻는다.
검증을 마친 모델은 API를 통해 접근 가능하며, 기업과 Web3 애플리케이션에 제공된다. 수요가 증가할수록 상위 모델들은 강력한 네트워크 효과(network effect)를 통해 가치를 배가하며, 모델 개발자와 데이터 제공자 모두에게 혜택이 돌아간다.
모든 거래, 거버넌스 결정, AI 모델 배포는 OPN 토큰을 통해 이루어지며, 기여자, 개발자, 사용자 모두가 이해관계자(stakeholder)로서 참여하게 된다.
OPN 토큰은 다양한 역할을 수행하며, 첫째로 AI 모델 펀딩에 사용된다. 초기 AI 오퍼링(IAO, Initial AI Offering)을 통해 사용자는 새로운 AI 모델의 런칭을 지원하기 위해 토큰을 스테이킹할 수 있다. 거버넌스는 탈중앙화되어 있어, OPN 보유자는 생태계의 주요 업그레이드, 모델 펀딩, 재정 관리 등을 결정하며, 신뢰할 수 있는 대표에게 투표권을 위임할 수도 있다.
또한 OPN은 OpenLedger의 Layer 2 네트워크에서 사용하는 네이티브 가스(gas) 토큰이다.
한편, 스테이킹은 책임성을 보장한다. 사용자는 참여하기 위해 OPN을 스테이킹해야 하며, 성과가 부진하거나 악의적인 행동을 하면 페널티가 부과된다. AI 서비스가 중요할수록 요구되는 스테이킹 규모는 증가한다. OpenLedger는 다양한 기능을 단계적으로 잠금 해제하는 다중 티어(multi-tier) 스테이킹 방식을 구상하고 있다.
Stakers receive rewards and get priority access to new tools and beta releases. More importantly, you can’t spin up a model or DataNet without showing “skin in the game,” ensuring you’re a serious participant.
스테이커(staker)는 보상을 받고 새로운 도구와 베타 버전에 우선 접근할 수 있는 권한을 얻는다. 무엇보다, 직접적 이해관계(skin in the game)가 없으면 모델이나 데이터넷을 런칭할 수 없으며, 이를 통해 진지하고 책임감 있는 참여자만이 생태계에 참여하게 된다.
몇 가지 생각들…

1. 데이터 기여(attribution)는 실제로 가능할까?
OpenLedger팀이 가진 가장 야심찬 아이디어는 "대규모로 데이터 기여 문제를 해결하는 것"이다.
"Payable AI" 개념은 매우 강력하다. Hugging Face가 오픈소스 AI 협력의 문을 열었지만, 그들의 수익화 모델은 구독(subscription) 및 관리형 서비스(managed services)에 의존한다. 데이터 제공자에게 진정한 금융적 인센티브는 부족한 상황이다. 반면 OpenLedger는 프로토콜 레이어에 데이터 기여와 보상 구조를 직접 내장하여 자체적으로 조정되는(self-regulating) 데이터 마켓플레이스를 목표로 하고 있다.
그러나 데이터 기여 문제는 AI 분야에서 특히 해결이 어렵다. 지금까지 보았듯이, 대규모 모델에 대한 데이터 기여를 추적하는 것은 여전히 열린 연구 과제이다. 과연 LoRA로 튜닝된 모델의 범위를 넘어 확장할 수 있을까?
OpenLedger팀의 생각은 이렇다: 혁신 기술은 초반에 어설퍼 보일지라도 결국 필연적이 된다. 기술을 강력하고 신뢰할 수 있도록 만드는 데는 시간과 연구개발이 필요하다. 이는 초창기의 영지식 증명(zero-knowledge proofs, ZK proof)이 발전한 것과 유사하다.
현재 OpenLedger 팀은 내부적으로 이미 기여 증명(PoA)을 구현하여 미세 조정된 모델 및 RAG 파이프라인에서 효과성을 입증한 상태다. 메인넷 출시가 가까워질수록 이 기술은 개발자들이 더욱 확장하고 혁신을 이루는 기반 인프라가 될 것이다.
만약 이를 성공적으로 달성한다면, OpenLedger는 AI 모델이 데이터 기여를 인식하고 보상하는 방식을 근본적으로 재정의하여 AI 기반 마이크로 경제(AI-driven microeconomies)라는 완전히 새로운 분야를 창조할 수 있다.
다만 수요 측면에서는 고민이 필요하다. 기업들이 실제로 탈중앙화된 시장에서 전문화된 데이터와 모델을 구매할 의사가 있을까? 대부분의 회사들은 이런 방식으로 AI를 구매하는 데 익숙하지 않다. 그보다는 기존 AI 기업과의 직접적인 파트너십을 선호할 가능성이 더 크다.
OpenLedger 팀은 데이터 기여 문제와 수요 창출 문제 모두 해결할 수 있다고 보고 있다. 이는 시간이 지나봐야 확실히 알 수 있을 것이다.
2. 탈중앙화 AI의 경쟁력은 바로 '전문화'에 있다
회의론자들은 탈중앙화 AI가 무제한의 자금을 가진 OpenAI, 구글, 앤트로픽(Anthropic)과 경쟁할 수 없다고 주장한다. 이는 AI의 미래가 오직 규모의 경쟁만이라고 전제하지만, 꼭 그렇지는 않다.
실제 경쟁력은 도메인 특화된 지능(domain-specific intelligence)에 있다. 범용 AI 모델(GPT-4, Claude, Gemini)은 인상적이지만, 특정 분야에서는 깊이가 부족하다.
단 하나의 회사가 모든 산업 분야와 연구 분야의 모델을 구축하고 관리하는 건 너무 비용이 많이 들고, 파편화된 작업이라 현실적이지 않다.
모든 산업과 연구 분야의 모델을 하나의 회사가 전부 구축하고 유지하는 것은 비용 면에서도, 관리 면에서도 비현실적이다.
OpenLedger의 가치는 전 세계 연구자, 전문가, 데이터 소유자들이 협력하여 전문화된 AI 모델이 활성화되는 마이크로 마켓(micro-market)을 형성하는 데 있다.
만약 OpenLedger가 빅테크 기업들이 제공하는 것보다 더 나은 도메인 특화 모델을 제공하는 생태계를 구축한다면 성공을 거둘 것이다. 그러나 플랫폼의 사용성이나 신뢰성, 유동성이 부족할 경우 참여자의 이탈로 인해 결국 시스템은 붕괴할 수 있다.
3. 이건 정말 중요하다
(표현이 다소 직설적이지만, 강조의 의미로 이해해 주길 바란다.)
SNS에서는 "AI가 사람들의 일자리를 대체할 것인가?"에 대한 논쟁은 넘쳐나지만, 정작 AI 모델 학습에 사용된 데이터의 기여자들에게 공정한 보상을 제공하는 문제는 거의 논의되지 않는다.
매일 AI 모델은 인간 전문가들의 데이터로 훈련받고 있지만, 정작 데이터를 제공한 사람들은 거의 보상을 받지 못한다.
그런 의미에서 "Payable AI"라는 개념은 단순한 마케팅 슬로건 이상의 깊은 울림을 준다.
사람들은 협동조합(co-op)을 구성해 매우 희귀하거나 가치 있는 데이터를 수집할 수 있다. 예를 들어, 농지 관련 지리공간 데이터, 정부 정책 문서 큐레이션 등이다. OpenLedger와 같은 플랫폼을 통해 이를 수익화할 수 있다. 이는 시간이 지남에 따라 다음과 같은 긍정적인 결과로 이어질 수 있다:
- 더 나은 데이터 품질 (모든 기여자가 데이터의 품질을 유지하려는 인센티브를 갖기 때문)
- AI의 환각 현상(hallucination) 감소 (도메인 특화 지식을 보유한 전문화된 모델을 사용하기 때문)
- 투명한 감사(auditing) (규제 산업에서 매우 중요한 요소)
한번 상상해 보자:
- 원예 전문가가 희귀 열대식물에 관한 데이터셋을 유지한다. 이 데이터를 학습한 AI가 농부들의 작물 질병 진단을 돕는다. 데이터가 사용될 때마다 데이터 소유자는 지속적으로 수익을 얻는다.
- 법률 연구자가 수십 년간의 판례 데이터를 모은다. 출판 대기업에 데이터를 일회성으로 판매하는 대신, AI가 특정 법률 의견이나 판례를 참조할 때마다 지속적으로 수익을 얻는다.
이것이 바로 도메인 전문가들이 거대 연구소에 모든 통제권을 넘기지 않고도 보다 광범위한 AI 생태계의 일부가 되는 방법이다. 이는 "사용자 생성 콘텐츠(user-generated content)" 개념을 "사용자 생성 데이터(user-generated data)"로 재정의하여 도메인 특화된 지능을 구축할 수 있게 한다.
AI 혁신의 다음 물결은 가장 거대한 모델을 만드는 것이 아니라, "적절한 작업을 위한 적합한 모델"을 만드는 것이 될 것이다.
🌈 Research Level Alpha
이 부분은 짧고 간결하게 정리하겠다.
알파(초기 정보를 활용한 기회)는 바로 OpenLedger의 테스트넷(testnet)에 참여해 노드를 운영하고, 다양한 모델을 데이터셋으로 미세 조정하는 실험을 하는 것이다. Epoch 2가 곧 시작된다. 이를 통해 OpenLedger가 무엇을 이루려 하는지 보다 명확히 이해할 수 있을 것이다.
추가로, 다른 이들을 노드 운영자로 초대하면 성공적인 추천(referral)에 대한 고정된(static) 보상을 받을 수 있으며, 특정 이벤트나 마일스톤 달성 시 추가 포인트도 지급된다.
마치며
우리는 지금 모두가 AI를 이야기하는 시대를 살고 있다. 크립토 열풍이 생성형 AI의 강력한 파급력에 가려져 있지만, 사실 이 두 분야의 결합이 가진 잠재력은 매우 크다.
- AI는 데이터를 수집하고, 검증하며, 데이터를 위해 지불하는 새로운 방식을 필요로 한다.
- 크립토는 자동화된 마이크로페이먼트와 탈중앙화된 거버넌스를 제공한다.
OpenLedger는 전문화된 데이터가 전문화된 모델을 강화할 수 있는 인프라를 구축 중이다. 만약 성공한다면, 이는 도메인 특화 AI를 위한 앱 스토어가 되어 데이터 소유자와 모델 제작자들이 지속적으로 수익을 창출할 수 있게 될 것이다.
다음에 AI가 계약서 작성을 돕거나 의료 진단을 내릴 때, 이 모든 것을 가능하게 한 데이터를 제공한 사람들이 마침내 정당한 보상을 받게 될 수 있다는 사실을 기억해주기 바란다.
내가 너무 낙관적이라고 말할지도 모르겠지만, 바로 이런 공정한 미래가 내가 Web3와 AI에 매료되는 이유이다.
OpenLedger가 성공한다면, 그런 미래가 현실이 될 날도 멀지 않았다.
건투를 빌며,
Teng Yan
주의사항
본 글에 기재된 내용들은 작성자 본인의 의견을 정확하게 반영하고 있으며 외부의 부당한 압력이나 간섭 없이 작성되었음을 확인합니다. 작성된 내용은 작성자 본인의 견해이며, (주)크로스앵글의 공식 입장이나 의견을 대변하지 않습니다. 본 글은 정보 제공을 목적으로 배포되는 자료입니다. 본 글은 투자 자문이나 투자권유에 해당하지 않습니다. 별도로 명시되지 않은 경우, 투자 및 투자전략, 또는 기타 상품이나 서비스 사용에 대한 결정 및 책임은 사용자에게 있으며 투자 목적, 개인적 상황, 재정적 상황을 고려하여 투자 결정은 사용자 본인이 직접 해야 합니다. 보다 자세한 내용은 금융관련 전문가를 통해 확인하십시오. 과거 수익률이나 전망이 반드시 미래의 수익률을 보장하지 않습니다.
본 제작 자료 및 콘텐츠에 대한 저작권은 자사 또는 제휴 파트너에게 있으며, 저작권에 위배되는 편집이나 무단 복제 및 무단 전재, 재배포 시 사전 경고 없이 형사고발 조치됨을 알려드립니다.



