Sharding: The Future of Ethereum Blockchain
[Xangle Originals]
By Ponyo
Translated by LC

Summary
- One way of increasing the throughput of a blockchain is a scalability technique called sharding
- Random sampling prevents the attacker from concentrating their power on one shard
- The fisherman’s dilemma can be solved via a technology called DAS (Data Availability Sampling)
Several years ago, Vitalik Buterin proposed the modular blockchain structure that leverages sharding and L2 as a way to solve blockchain trilemas (refer to: Ethereum 2.0 Blueprint: Modular Blockchain). Once the modular blockchain is completed, the shard chain will mainly function as the data availability layer, but there is another reason why sharding is drawing attention. In the long term, sharding is the only solution that can scale to millions of TPS of the L1 blockchain while remaining highly decentralized, and it is an indispensable technology for Ethereum to become a true world computer.
This article dives into the basics of sharding, from its definition to the overall architecture and FAQs.
1. What is sharding?
Currently, most L1 block chains handle all transactions in the network for each node. This method ensures excellent security, but since all nodes have to store the same data (user funds, contract code, storage, etc.) and agree on each transaction, this presents clear limitations in terms of storage and salability. For this reason, Bitcoin and Ethereum, known to be the most secure blockchains out there, can only process 7 and 15 TPS, respectively. To overcome these limitations, sharding has been proposed as an effective scaling solution by Vitalik Buterin.
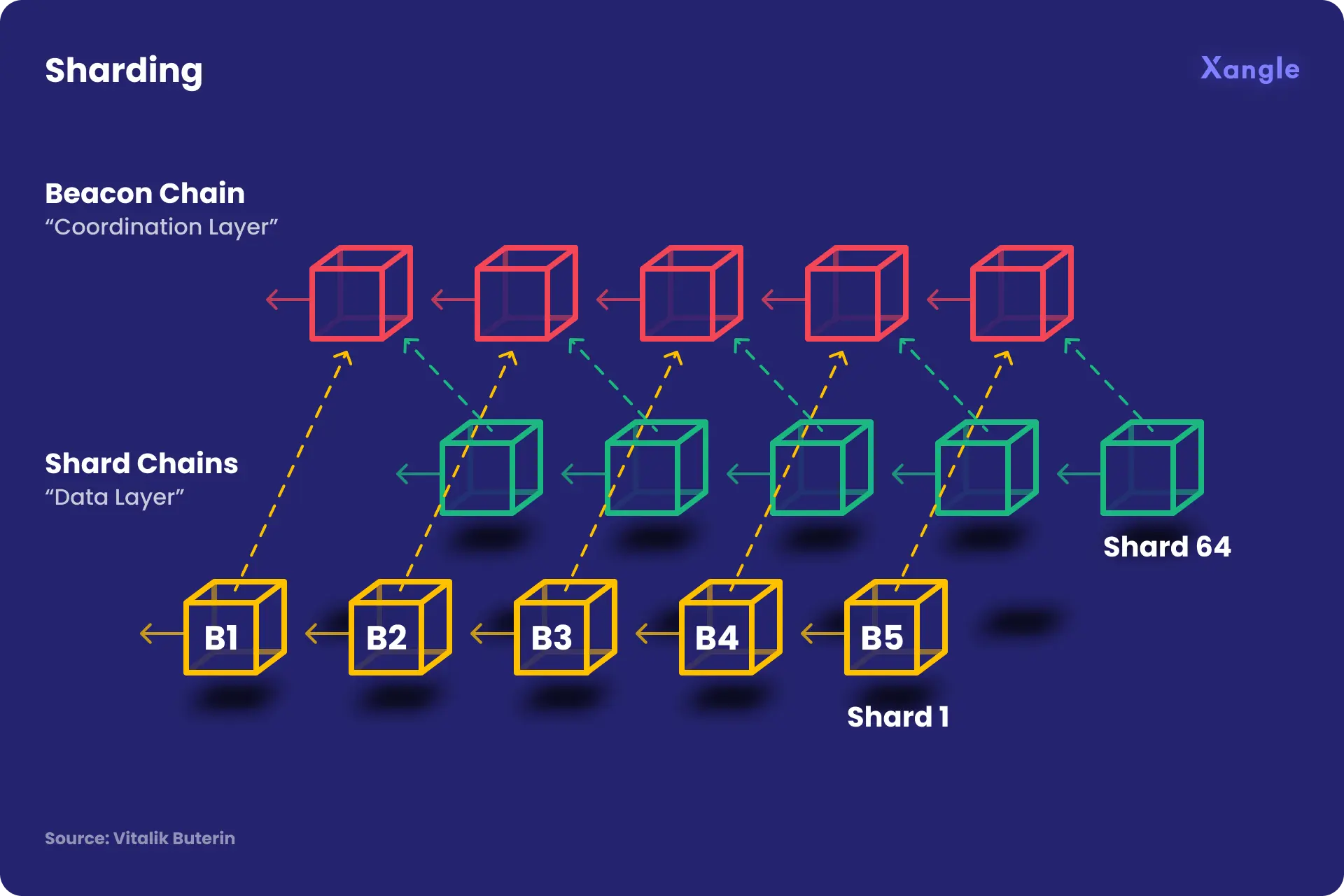
Sharding is a form of data partitioning that breaks down the L1 blockchain into several chains or shards. In the case of the Ethereum chain, shard chains are created by sharding the Ethereum chain into smaller pieces. Meanwhile, nodes are divided by group of which each of them is allocated to each shard. This decreases the workload of network validators by requiring each validator to only store and manage one shard of the network instead of the whole blockchain. Below are certain rules and patterns that should be followed when converting the transactions into smaller shards.
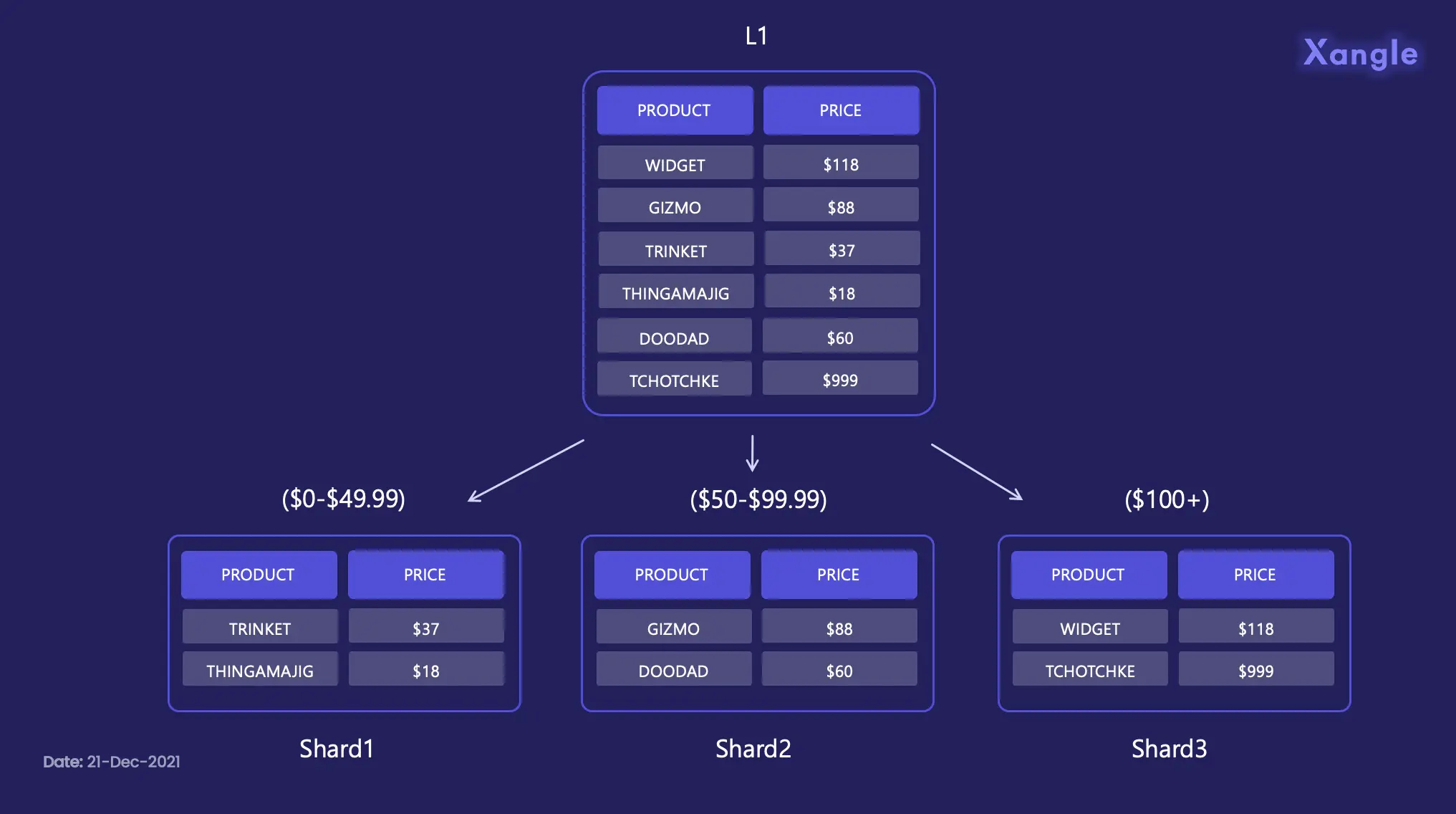
Every shard will have its own unique transaction group as below.

Shard ID: The ID that the transaction group belongs to
Pre state: The state of the root of that particular shard before the transactions were put inside it
Post state: The state of that root after you put the transaction group inside it
Receipt root: A receipt root that acknowledges the fact that the transaction group has entered into the root
2. Random Sampling
Suppose that you have a PoS blockchain with 10,000 validators, and you have 100 blocks that need to be verified. We first randomly shuffle the validator list and assign the first 100 validators in the shuffled list to verify the first block, the second 100 validators to verify the second block, etc. By doing so, instead of every block being broadcasted through the same P2P network, each block is broadcasted on a different sub-network (shard), and nodes need only join the subnets corresponding to the blocks that they are responsible for. The group of 100 validators is called a committee.
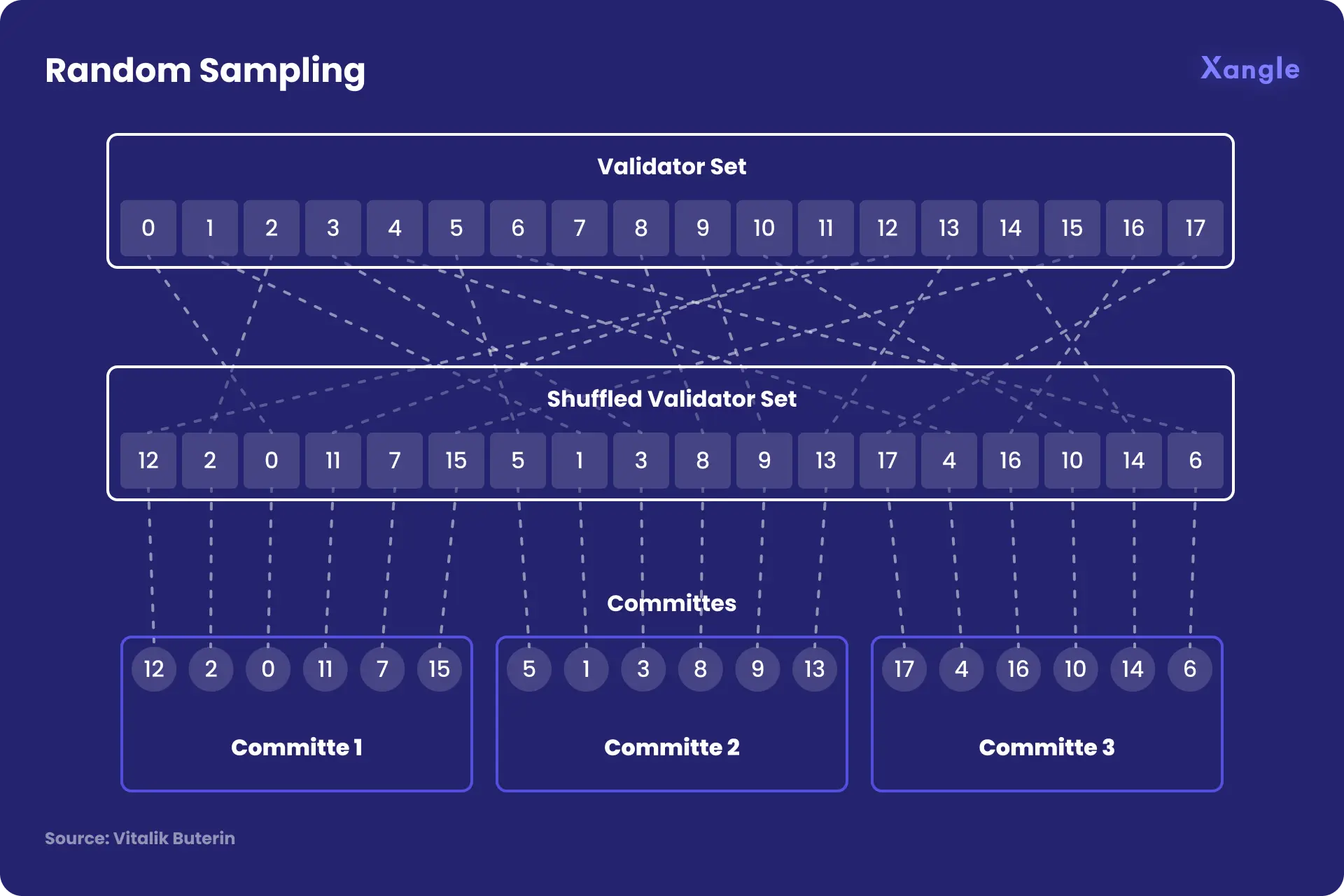
When a validator verifies a block, they publish a digital signature attesting to the fact that they did so. Everyone else, instead of verifying 100 entire blocks (a monolithic blockchain method), now only verifies 10,000 signatures - a much smaller amount of work.
3. Advantages of sharing
No. of validator node ↑ = Scalability ↑, Decentralization ↑, Security ↑
- No. of validator node ↑ = Scalability ↑
In the case of the existing L1 blockchain, when the number of nodes increases (or when the security increases), the verification speed becomes slower (or less scalable), so one has to be sacrificed in order to gain the other. On the contrary, in sharding, the number of nodes increases when the number of committees increases, which in turn increases the network processing capacity.
Unlike monolithic blockchains, where all transactions must be verified together, the committee of each shard chain has a set of blocks to verify. Therefore, an increase in the number of nodes increases the number of committees, which means that more blocks can be verified at the same time.
- Validator node requirement ↓ (Minimum specification of hardware↓)
Because a node can sync with the corresponding shard without needing to sync to a massive blockchain, a node can be created with much less hardware specification (Perhaps a raspberry pi alone can run an Ethereum node). With less hardware specification, the number of nodes will increase, improving the decentralization and security of the blockchain.
4. Shard chains vs Individual chains
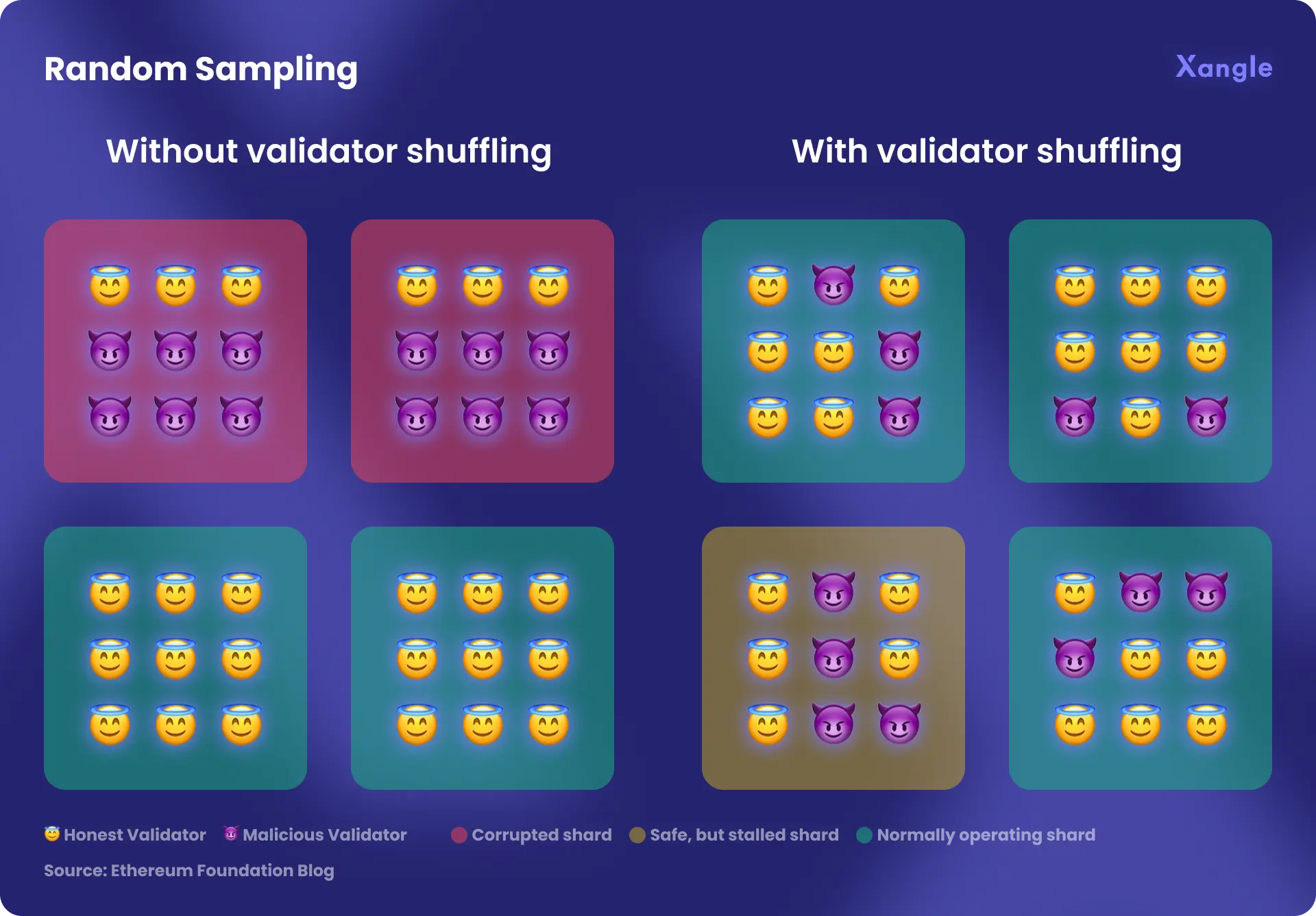
Random sampling enables the shard chain to prevent the attacker from concentrating their power on one shard. Ethereum aims to maintain the security of the blockchain via random sampling. The biggest problem with sharding is that attackers do not need to attack 51% of network hash rate, but only need to secure 51% within a single shard to dominate the shard.
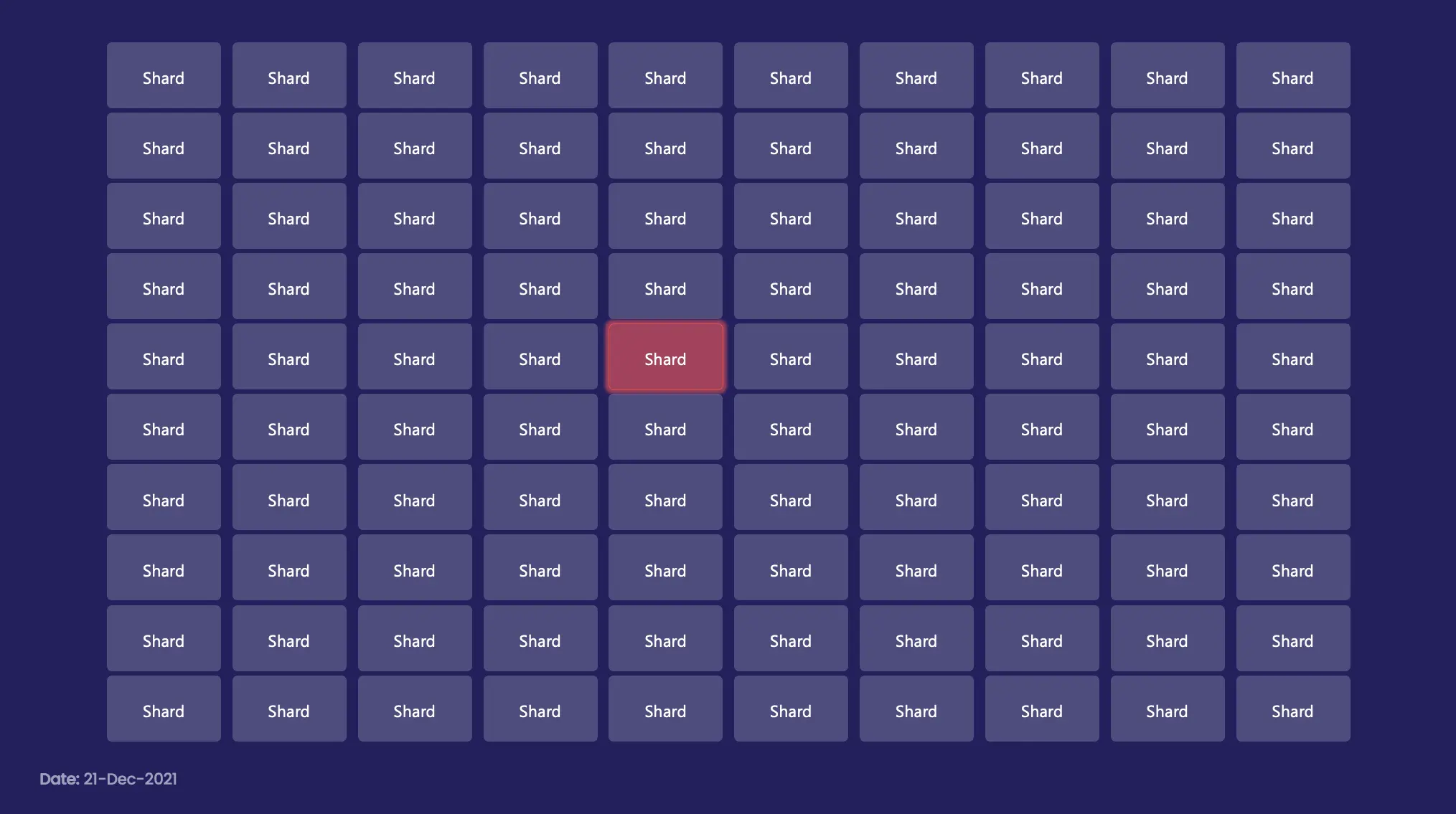
To secure a single shard, attackers must dominate the committee. As shown below, if 30 to 40% of the total number of validator nodes participating in the network are attackers, more than a majority of the attackers could possibly penetrate the committee if random sampling is not applied. Applying random sampling, however, that possibility will be significantly lowered, and if if an attacker has less than 30%, it’s virtually impossible. On the other hand, random sampling is not applied to individual chains, making it much easier for attackers to dominate the chain.
5. Fisherman’s dilemma
It was previously mentioned that shard chains in Ethereum will act as the data availability layer. The problem here is that there is too much data to check to publish it on chain. For example, someone could claim that data X is available without publishing it, wait to get challenged, and only then publish data X make the challenger appear to the rest of the network to be incorrect. This is expanded on in the fisherman’s dilemma below.
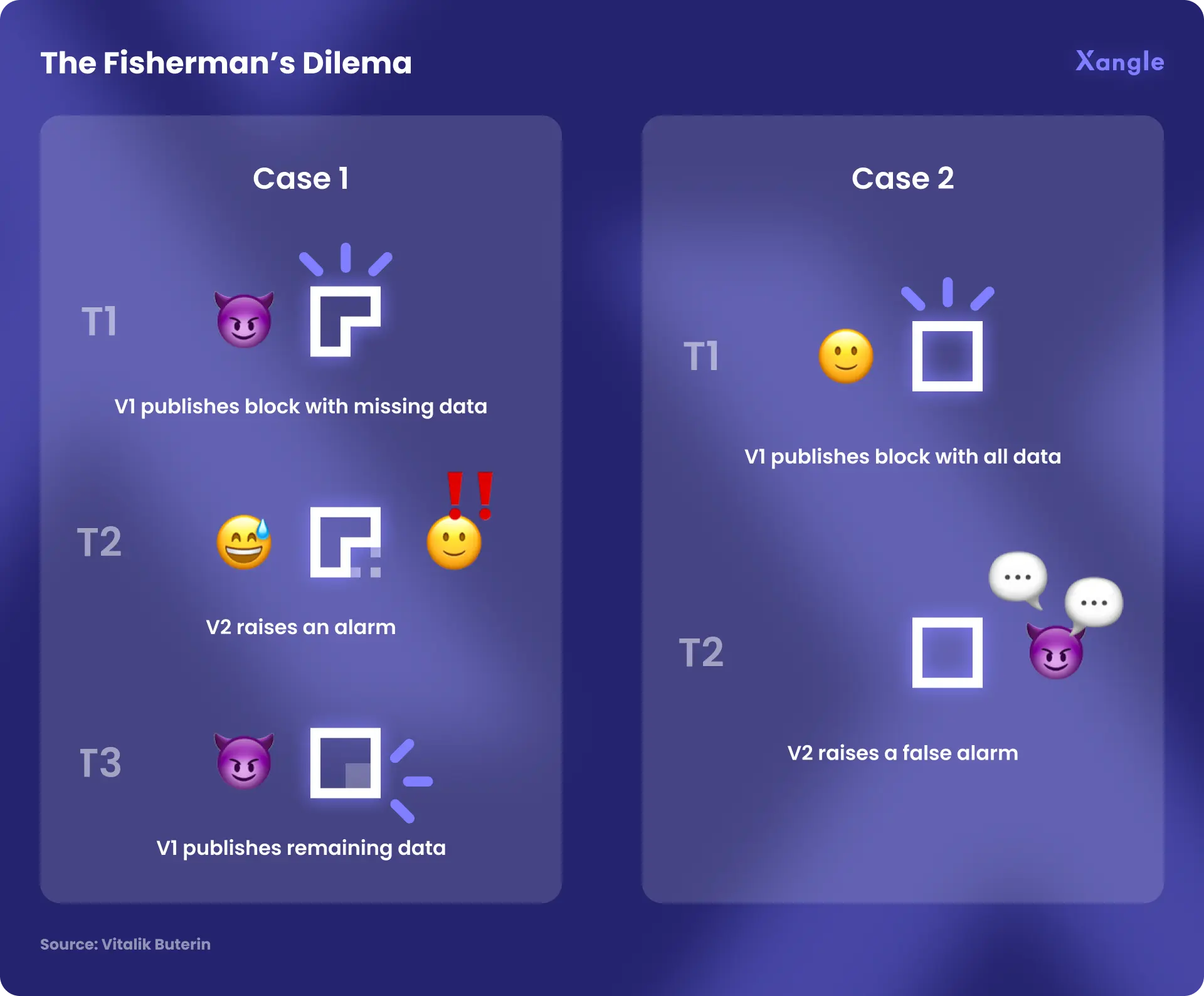
In the diagram above, case 1 and case 2 are indistinguishable to anyone who was not trying to download that particular piece of data at the time, making it difficult to determine which one is the evil publisher and which one is an honest challenger (V1, V2). So, it just seems that one of the two published blocks with missing data, without knowing who was right and who was wrong. This is the fisherman’s dilemma.
6. Solution to the fisherman's dilemma - DAS (Data Availability Sampling)
So, how do you check a specific data is available without actually trying to download it? Vitalik suggests that it could be done through DAS technology.
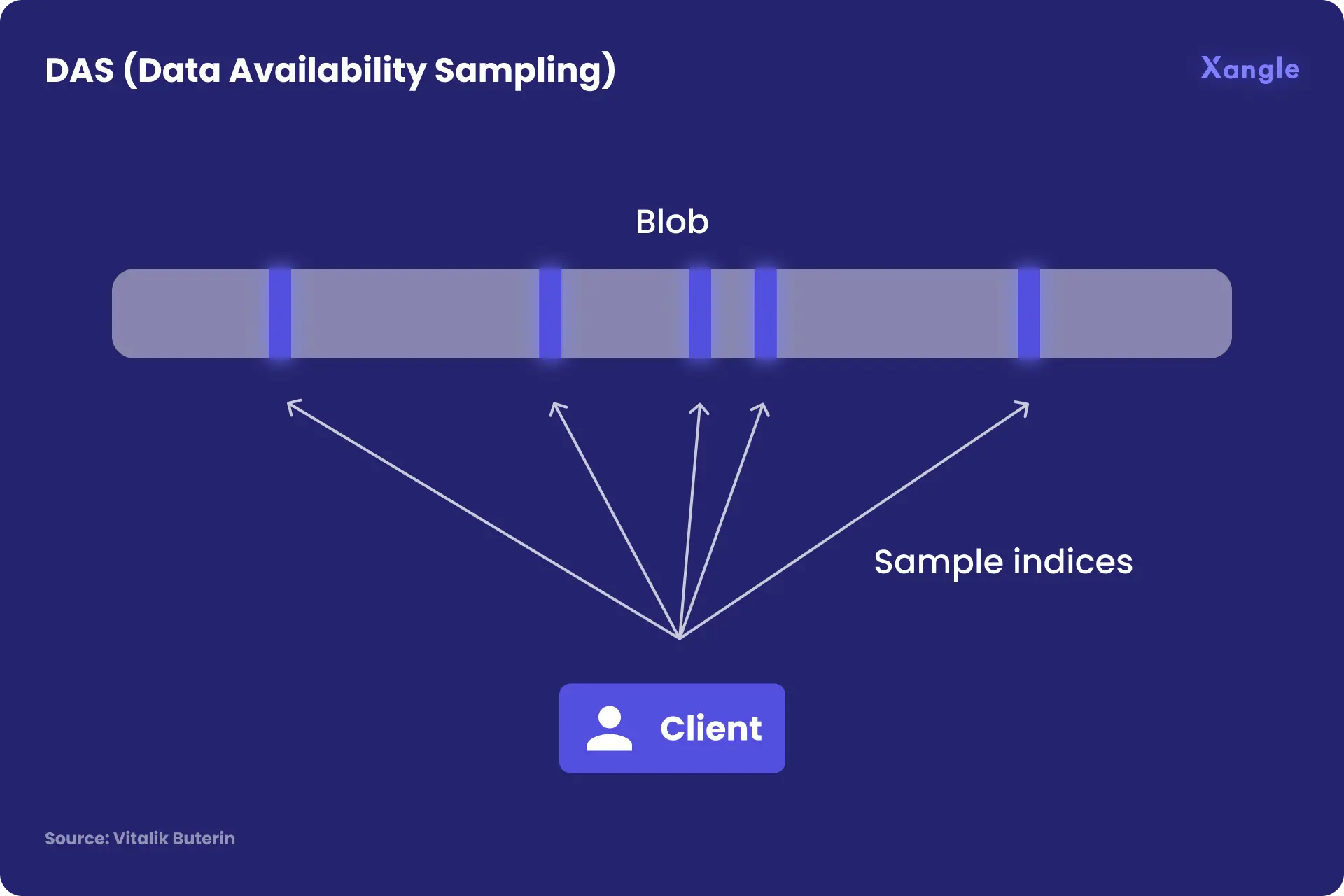
Each client (including nodes not participating in staking) performs DAS on each block by simply randomly selecting a constant number of positions in the block instead of downloading the entire data. The goal of DAS is to verify that at least 50% of the data is available on chain (If at least 50% of a block's data is available, then actually the entire block is available). DAS is efficient in theory, but it is not yet a proven technology.
Bottom line
Ultimately, blockchain is very likely to take the form of a modular blockchain leveraging sharding. Looking at the performance of highly-sclable, high-speed L1 blockchains such as Solana, you might question whether sharding should really be implemented or not. The bottom line is that the modular blockchain that leverages sharding and rollups is much more efficient and economically sustainable, so my answer to the question is yes, sharding is necessary. In the next article, we will take a closer look at modular blockchains vs high-performance L1 blockchains.
Disclaimer
I confirm that I have read and understood the following: The information contained in this article is strictly the opinions of the author(s). This article was authored free from any form of coercion or undue influence. The content represents the author's own views and does not represent the official position or opinions of CrossAngle. This article is intended for informational purposes only and should not be construed as investment advice or solicitation. Unless otherwise specified, all users are solely responsible and liable for their own decisions about investments, investment strategies, or the use of products or services. Investment decisions should be made based on the user’s personal investment objectives, circumstances, and financial situation. Please consult a professional financial advisor for more information and guidance. Past returns or projections do not guarantee future results.
Xangle or its affiliated partners own all copyrights of the written or otherwise produced materials and content provided on the platform. Any illegal reproduction of such content, including, but not limited to, unauthorized editing, copying, reprinting, or redistribution will result in immediate legal actions without prior notice.


![[Xangle RWA Series] Solana RWA: A Look at the Key Players](https://resource.xangle.io/files/content/F779A005246C0299246537AACB3A39F2_1782287059970.webp)

