
tigerant_btc
Research Analyst/
Xangle
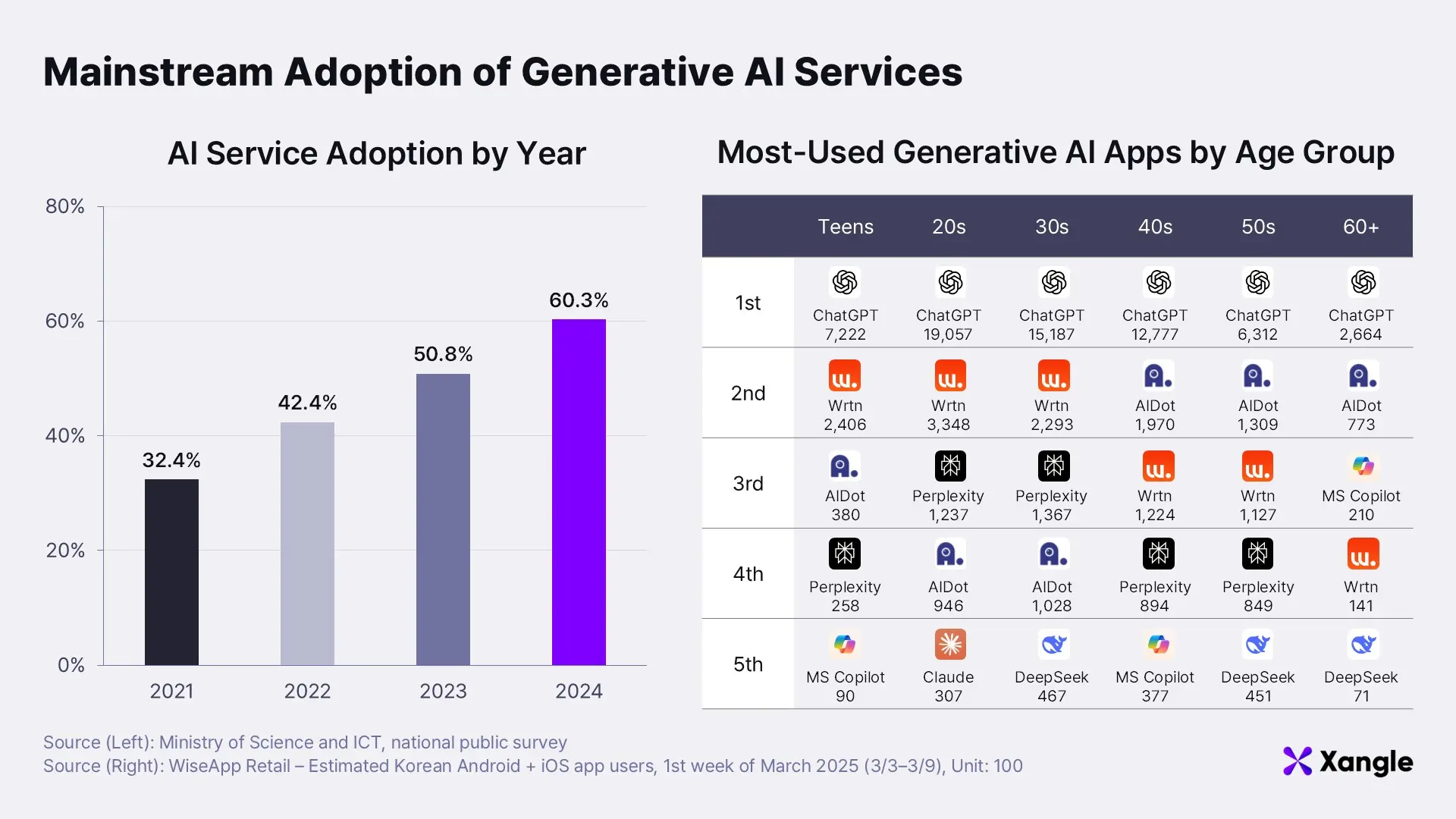
How deeply is artificial intelligence embedded in your daily life? From news reports of students struggling with grading issues after submitting AI-generated assignments, to anecdotes of office workers who used AI to draft love letters before copying them by hand for a personal touch—the presence of AI has become far more noticeable than it was at the time of ChatGPT's initial release. According to a survey conducted by South Korea’s Ministry of Science and ICT, nearly 60% of 60,229 respondents had used generative AI services as of 2024. In other words, six out of ten Koreans now interact with AI in their everyday lives.
A closer look at how people use AI reveals that ChatGPT dominates across all age groups. The same survey found that users primarily turn to generative large language models (LLMs) like ChatGPT for information retrieval (81.9%), document editing assistance (44.4%), and foreign language translation (40%). AI has effectively assumed the role of an all-purpose assistant or digital secretary.
For many who have experienced AI firsthand, the dream is to one day rely on it as a true personal assistant. I share that vision, and consider the fictional AI assistant Jarvis from the Iron Man films to be one of the most compelling representations of what AI could become. While a significant technological gap remains between current AI systems and the capabilities portrayed in fiction, advancements are steadily progressing in that direction.
Building an AI assistant like Jarvis would require several technical components. Given that Jarvis operates seamlessly across a range of wearable devices—such as the Iron Man suit, digital glasses, and wristwatches—it likely relies on low-power, efficient, and highly personalized AI models that function as a sort of cognitive engine. (Although one might point out that the Iron Man suit is powered by an arc reactor, the films also depict it running out of power during intense combat, underscoring the importance of efficiency.) To perform a wide range of tasks, such an AI would also need to leverage modular agent tools with broad compatibility across devices and platforms.
 Source: "The AI Assistant from Iron Man Comes to Life” – Nobel Science
Source: "The AI Assistant from Iron Man Comes to Life” – Nobel Science
Bringing Jarvis-like capabilities into reality depends on two essential components: Specialized Language Models (SLMs) and high-quality domain-specific data. SLMs are lightweight, efficient models tailored to specific domains. Compared to general-purpose LLMs like ChatGPT-4o, they offer significantly greater accuracy and performance within their areas of specialization while consuming far fewer resources.
Developing these models, however, requires access to expert-curated data—not just information scraped from the web, but specialized knowledge created and validated by professionals in their fields. AI trained under these conditions can progress beyond generic versatility and toward deep, reliable expertise—bringing us closer to truly intelligent and useful assistants.
OpenLedger presents a clear and ambitious vision built around this very idea. Under the narrative of “An AI blockchain where data and AI models become profitable,” OpenLedger aims to develop a platform for creating domain-specialized AI models powered by verified expert data. The sections that follow will explore why OpenLedger has chosen to pursue this SLM-centered approach, and how it plans to integrate blockchain and Web3 technologies to support this future.
Before exploring why OpenLedger is centered on Specialized Language Models (SLMs), it is essential to understand their growing significance within the broader trajectory of AI development.
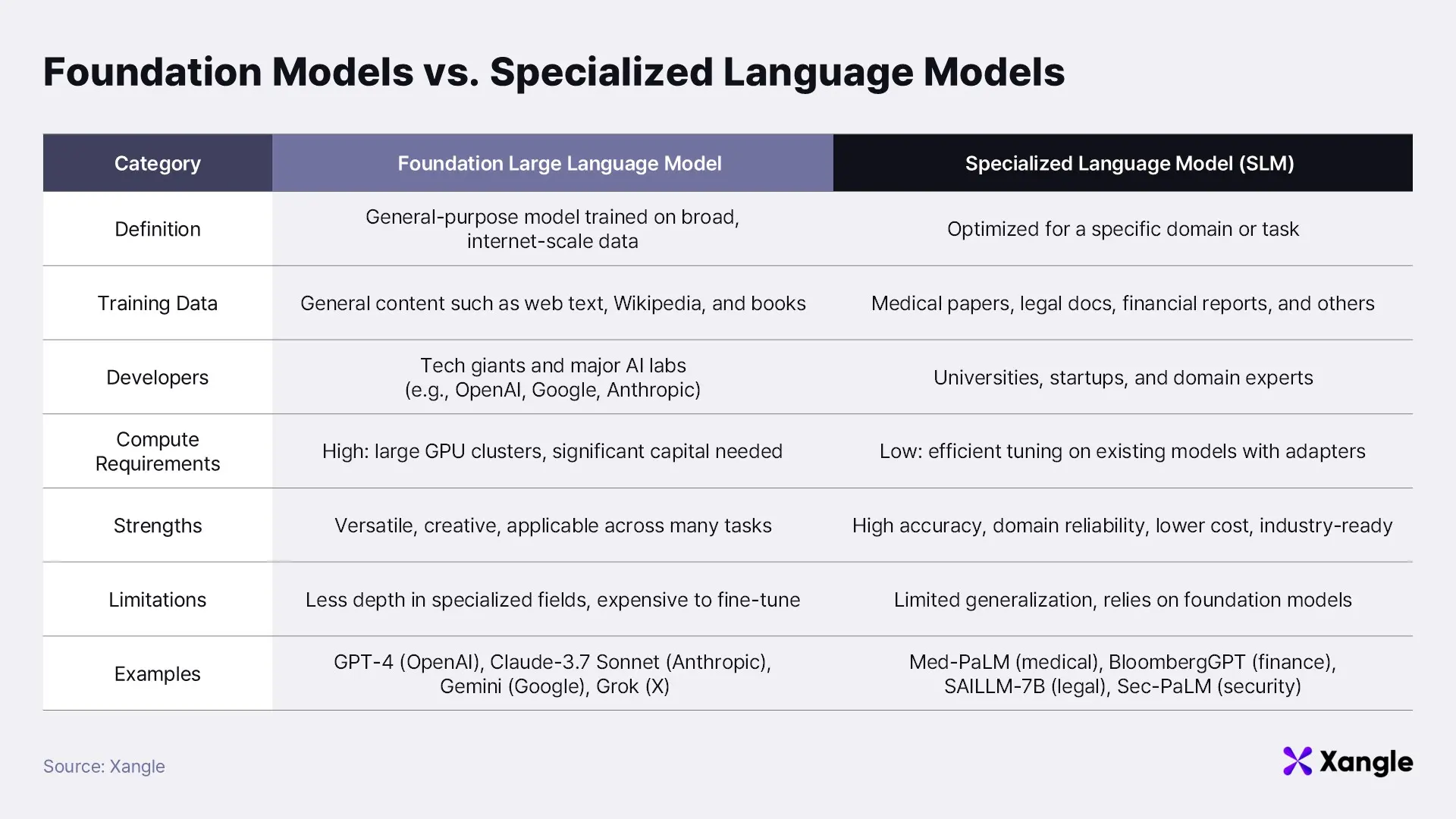
Models like GPT-4, widely used in services such as ChatGPT, are classified as general-purpose or foundation models. These large-scale models are capital-intensive, requiring vast datasets and immense computing power to train. Their strength lies in their versatility—they perform reasonably well across a wide range of tasks—but this very generality limits their depth in any one specialized domain. OpenLedger captures this limitation with a simple analogy: “A general practitioner cannot perform a specialized heart surgery.” While GPT-4 excels at answering broad questions, writing code, or summarizing content, it often lacks the depth to provide precise insight into narrow fields like cutting-edge medical research, complex legal analysis, or quantitative financial modeling. Increasing the size of the foundational model is not a sufficient solution to this problem. In fact, a study by OpenAI (Scaling Laws for Neural Language Models, Kaplan et al., 2020) found that performance gains from scaling model size diminish significantly beyond a certain point.
This is where SLMs enter the picture. These models are optimized for specific domains and are capable of grasping field-specific knowledge and contextual nuance. For example, a healthcare-focused SLM can offer far more accurate information on disease diagnosis, treatment methods, and recent medical breakthroughs than a general-purpose LLM. If a foundation model is like a freshman excelling in general education courses, an SLM is akin to an upperclassman who has declared a major—developing greater expertise in a chosen field.

OpenLedger envisions a future not dominated by a single model, but rather powered by thousands of specialized AI models, each delivering deep expertise in its own domain. The platform it proposes is designed to enable these SLMs to interoperate and complement one another—creating a collaborative ecosystem of domain-specific intelligence capable of producing real, specialized value across professional fields.
Building and sustaining such an SLM-centric platform, however, demands more than layering AI applications on top of a general-purpose blockchain. It requires foundational infrastructure that is purpose-built for AI—one that supports data attribution, incentivized collaboration, and verifiable contribution. This need is precisely why OpenLedger is pursuing a novel approach: the development of an “AI blockchain.”
The current AI industry lacks a functioning compensation framework for data contributors. When directly asked about this issue, ChatGPT acknowledged the limitation, stating, “OpenAI has never directly compensated individual creators for the large-scale text or image data publicly available online used to train GPT models.” It further explained that “data collected via web crawling and scraping is treated as fair use or public domain, with no licensing fees or royalties applied.” This response highlights the prevailing norm in AI development: critical training data is sourced without direct compensation to its creators.

Despite playing a vital role in enhancing model performance, data creators and providers remain uncompensated. OpenLedger recognizes this as a structural flaw—and views it as both a challenge and an opportunity. Unlocking the full potential of SLMs requires a steady inflow of high-quality, domain-specific data. But that inflow will only be sustainable if contributors are fairly rewarded. To address this, OpenLedger is building a blockchain infrastructure purpose-built for AI, distinct in both design and intent from general-purpose blockchains.
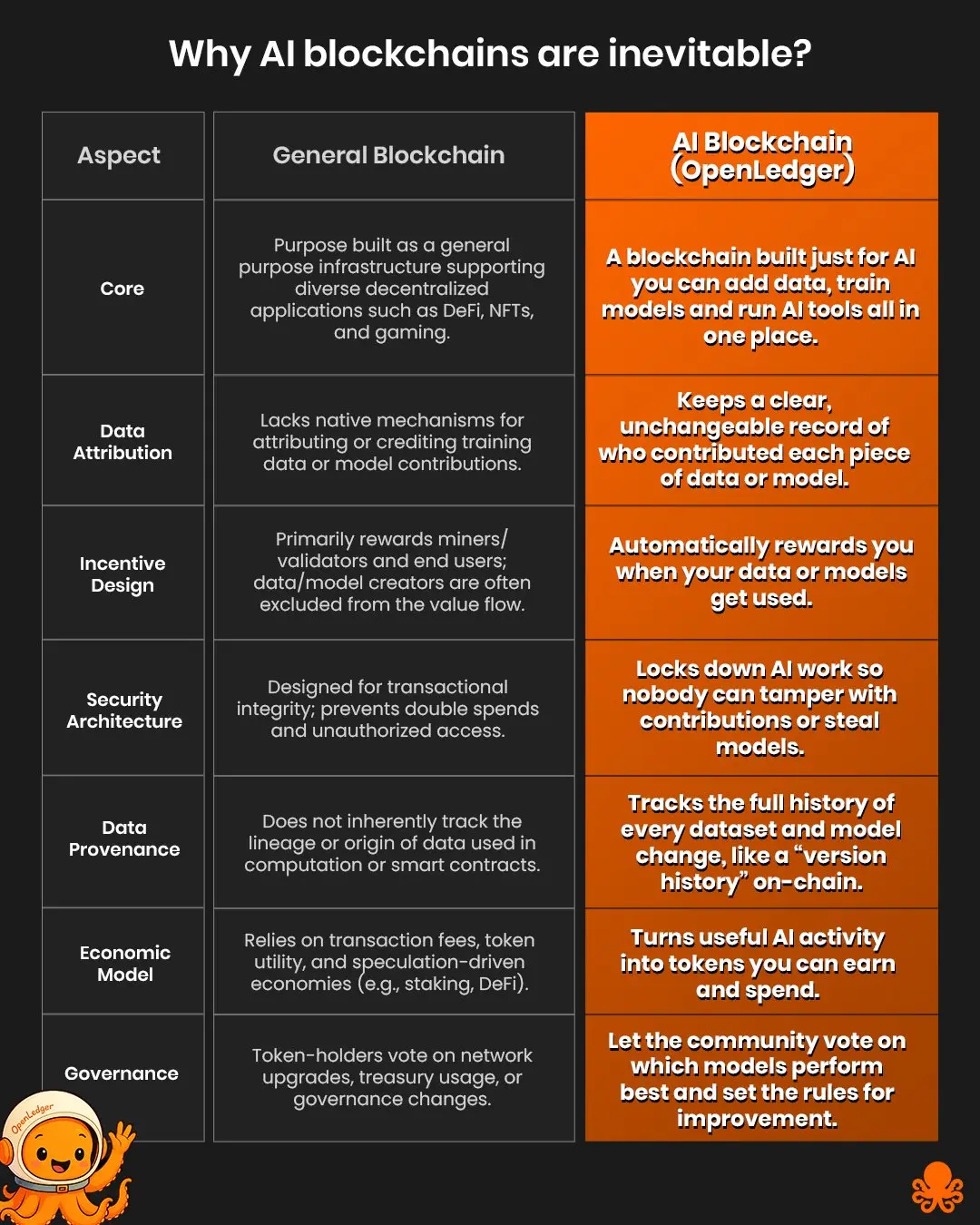
OpenLedger’s concept of an AI blockchain leverages the strengths of existing blockchain technologies but is fundamentally tailored for AI development and utilization. General blockchains typically optimize for decentralized recording and management of financial transactions or asset ownership. General-purpose blockchains such as Ethereum are designed as infrastructures supporting diverse decentralized applications like DeFi, NFTs, and gaming, yet they lack the specialized capabilities required for AI development and operation. In contrast, an AI blockchain is specifically engineered to support the entire lifecycle of AI development—from data contributions and model training to executing AI tools—all within a unified platform.
The distinctions between AI blockchains like OpenLedger and general blockchains can be summarized across four key dimensions:
1. Data Attribution
General blockchains do not provide native mechanisms for tracking who contributed specific data or models. In contrast, OpenLedger records these contributions immutably on-chain, ensuring transparency and enabling provable ownership. This creates the necessary foundation for rewarding contributors whenever their data is used.
2. Incentive Design
In general-purpose blockchains, rewards flow primarily to miners, validators, or end users. Data providers or model developers are often left out of the value chain. AI blockchains reverse this dynamic. By linking compensation directly to data usage or model deployment events, OpenLedger ensures that contributors are automatically and proportionally rewarded.
3. Data Provenance
Blockchain applications today typically do not track the lineage of data used in smart contracts or computations. OpenLedger, by design, captures the full audit trail of datasets and model revisions, much like version control systems. This enables verifiable transparency and dramatically enhances trust in AI systems.
4. Economic Model
While general blockchains often rely on speculative mechanics—trading, gas fees, token appreciation—AI blockchains introduce intrinsic value creation. OpenLedger aligns rewards with actual utility: meaningful contributions to AI development, including data quality, model accuracy, and performance. This represents a shift toward a productivity-driven crypto economy.
These structural differences allow OpenLedger to address some of the most pressing issues in AI development today: inadequate contributor rewards, opaque model training, and a lack of access to verified data. Just as blockchain technology once redefined the financial system, AI blockchains now hold the potential to redefine the development and deployment of artificial intelligence itself.
 Source: X(@OpenledgerHQ)
Source: X(@OpenledgerHQ)
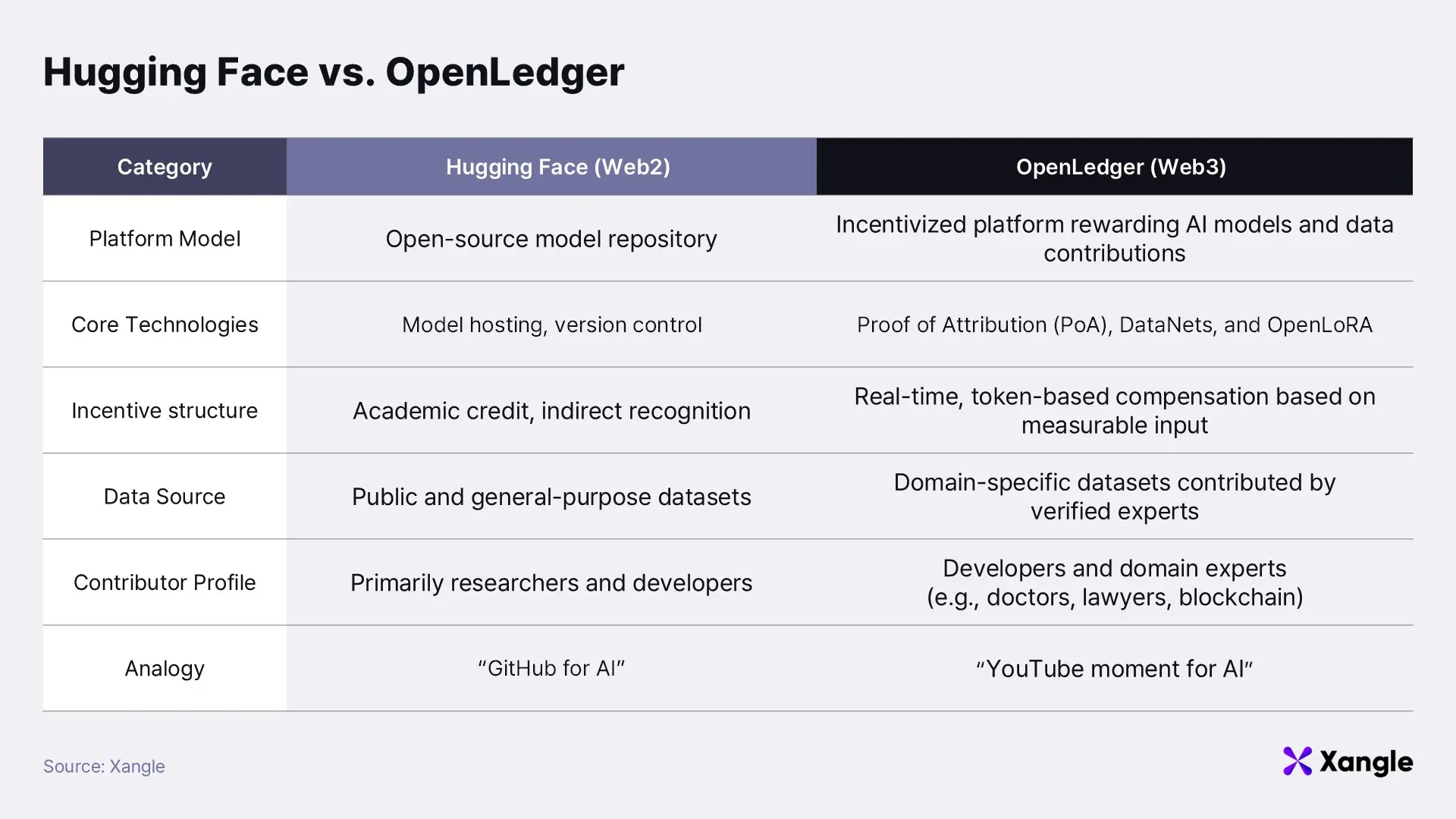
While concepts like SLMs and AI blockchains are central to OpenLedger’s vision, they may appear abstract—particularly to investors less familiar with AI. To ground these ideas, it is helpful to draw a comparison with one of today’s most successful AI platforms: Hugging Face. This Web2-based open-source hub for AI models and datasets has played a pivotal role in supporting researchers and startups around the world. OpenLedger seeks to extend Hugging Face’s strengths by incorporating Web3 technologies, thereby introducing stronger economic incentives and unlocking new synergies.
 Source: Hugging Face, often referred to as the “GitHub of AI,” where diverse models and datasets are shared openly.
Source: Hugging Face, often referred to as the “GitHub of AI,” where diverse models and datasets are shared openly.
Hugging Face’s rapid rise can be attributed to its collaborative, community-driven model that breaks down the traditional barriers to entry in AI development. Building powerful models like GPT-4 typically requires immense computing resources and substantial capital investment. These models are proprietary, inaccessible to most researchers, and impossible to run on standard consumer hardware. Developing such systems often demands thousands of high-performance GPUs and hundreds of millions of dollars—resources generally limited to tech giants like Microsoft and Google or heavily funded startups like OpenAI and Anthropic.
This concentration of AI development within a small elite has significantly slowed the democratization of the field, prompting a key question in academia and startups alike: How can we build practical, useful AI with limited resources? In response, open-source alternatives like Meta’s LLaMA and Mistral AI’s Mixtral emerged, igniting demand for tools that specialize and fine-tune these foundational models efficiently.
Hugging Face recognized this shift and provided the infrastructure needed to build high-quality models with limited computing resources. More than a code repository, the platform supports model versioning and dataset sharing—enabling researchers and small startups to use lightweight fine-tuning methods such as LoRA (Low-Rank Adaptation) to develop domain-specific models.
At the heart of Hugging Face’s success is its virtuous cycle of “derivation, performance improvement, and open sharing.” Research teams build on base models like LLaMA, fine-tune them for specific tasks, and share the results back with the community. For example, Vicuna was adapted for natural dialogue by fine-tuning LLaMA on human-AI conversations. Alpaca, developed at Stanford, was tailored for instruction-following tasks, while WizardLM was optimized for complex queries and expert-level outputs. Each of these models was openly shared, reinforcing a cycle of innovation and collaboration.
This process not only enabled contributors to validate and publish their model performance through academic channels, but also fostered a culture of trust and transparency. The open availability of models allowed the wider community to reproduce and verify results, narrowing the performance gap between open-source and commercial models at a remarkable pace. Hugging Face leveraged this user base to expand into enterprise solutions, hosting services, and professional support.
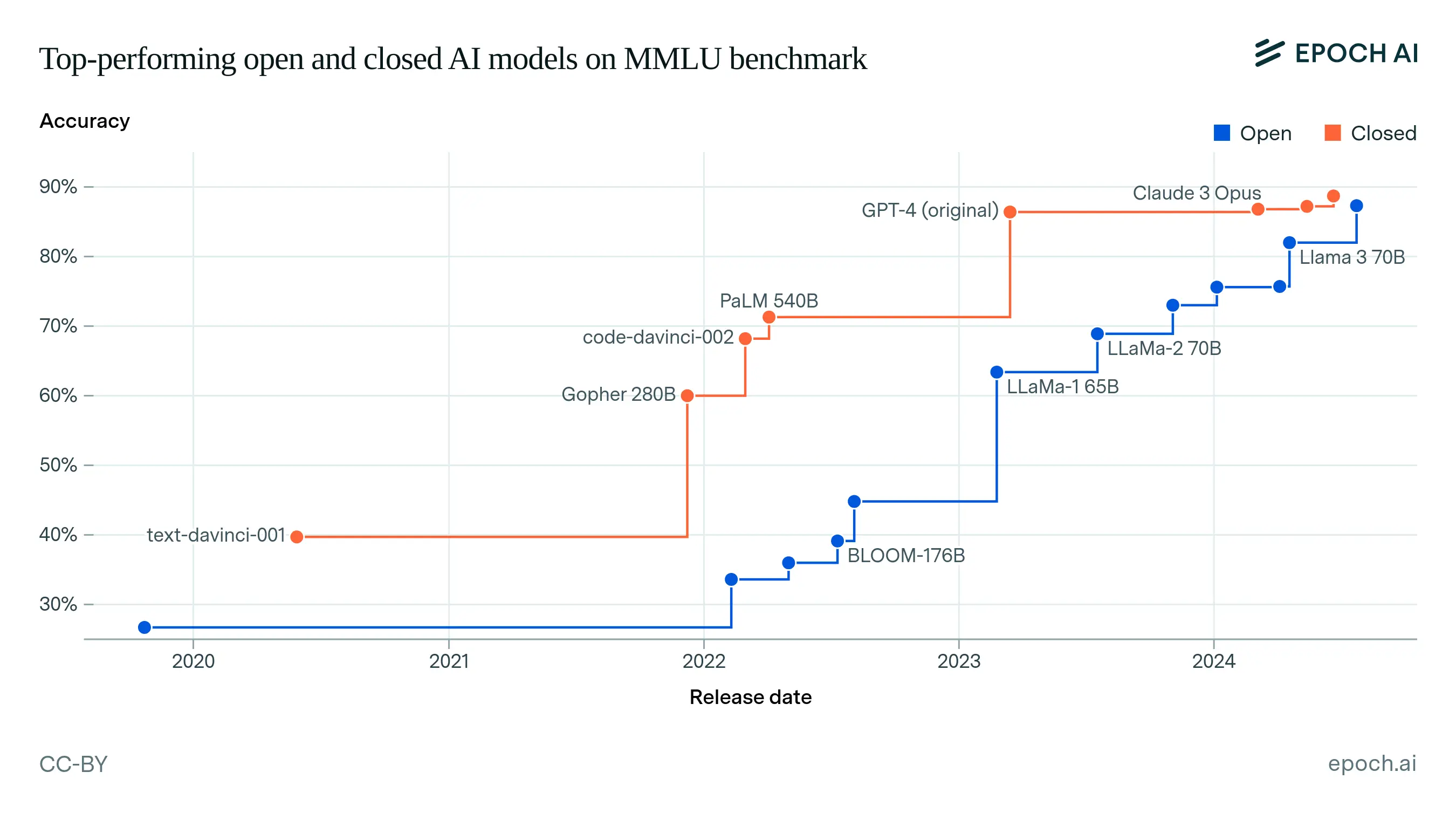 Source: Epoch AI – The performance gap between open-source and proprietary AI models is closing rapidly.
Source: Epoch AI – The performance gap between open-source and proprietary AI models is closing rapidly.
Still, Hugging Face faces structural limitations. Most contributions are driven by academic recognition or indirect reputational benefits. This leaves little incentive for domain experts—such as doctors, lawyers, or financial analysts—to share specialized knowledge for AI training. Even if their models are successfully commercialized, there are natural hesitations around openly sharing proprietary or revenue-generating work. In addition, open-source models are often trained on publicly available datasets, limiting their access to in-depth, domain-specific knowledge. Finally, Hugging Face does not offer a built-in mechanism to track the data sources underlying model outputs, making it difficult to measure individual contributions or provide fair compensation.
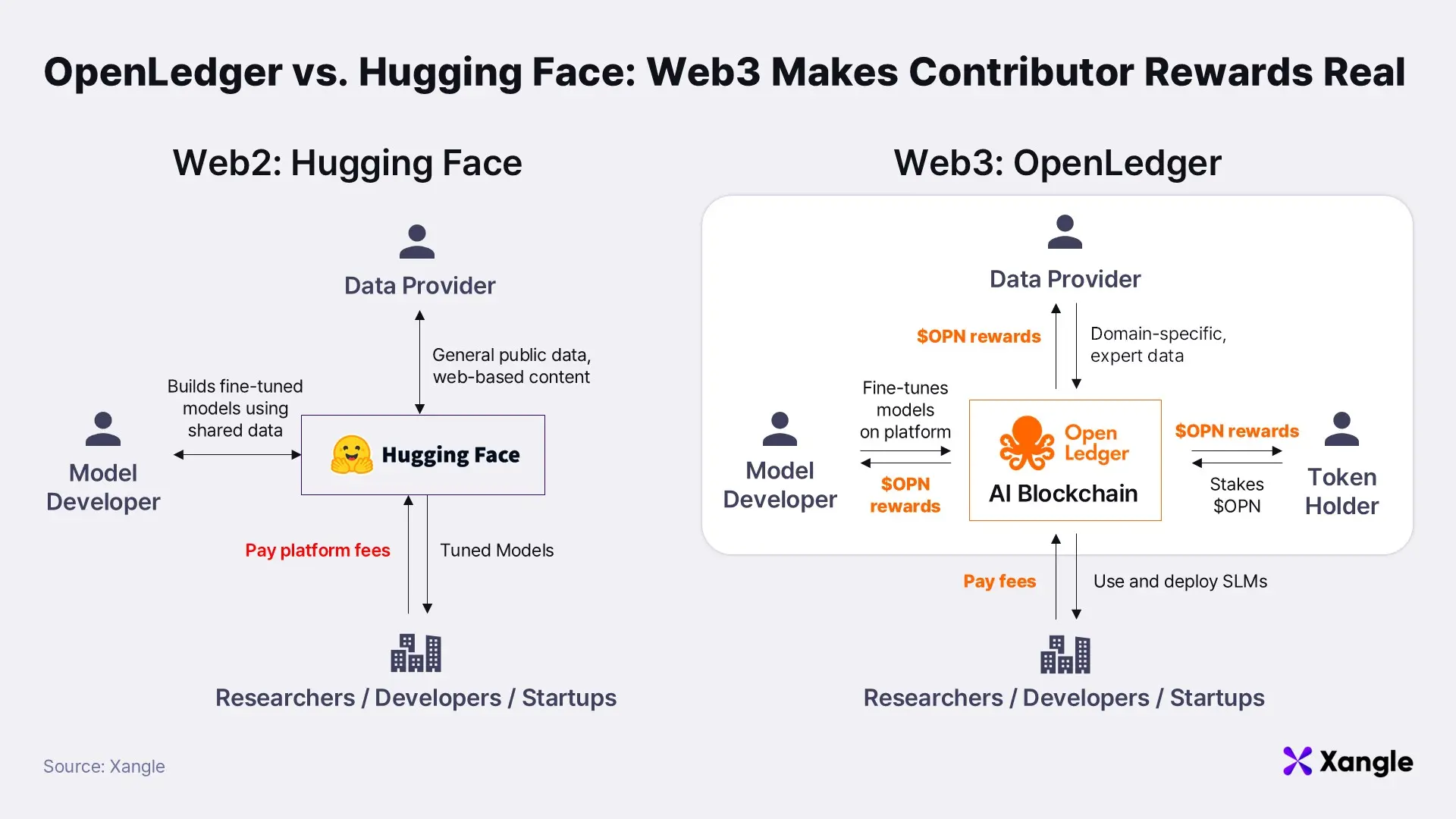
OpenLedger seeks to overcome these limitations by leveraging Web3. Its core differentiator is the concept of “Payable AI”—a framework where contributors are continuously compensated whenever their domain expertise is used by an AI model. To support this, OpenLedger introduces DataNets, domain-specific data networks designed to systematically collect and validate high-quality expert datasets across verticals such as medicine, law, finance, and cybersecurity. These curated datasets serve as the foundation for building specialized SLMs.
A critical component of this ecosystem is the Proof of Attribution (PoA) mechanism, which enables transparent, verifiable tracking of how much a particular dataset influences a model’s output. PoA provides the technical backbone for rewarding data contributors fairly based on the value their data generates. Once verified, this data can be directly applied via OpenLedger’s no-code model tuning tools, enabling users to create and publish their own SLMs on the platform.
By introducing a Web3-based incentive structure, OpenLedger strengthens the collaborative ethos of open-source platforms while addressing their economic blind spots. This approach not only encourages the continuous supply of expert-verified data but also accelerates the development of specialized models across industries. The result is a new AI development paradigm—one that is SLM-centric, economically inclusive, and technically transparent.
The next section will explore how OpenLedger technically integrates these concepts—SLMs, DataNets, and PoA—into a cohesive platform architecture designed to deliver on the vision of Payable AI.
To build its Payable AI platform, OpenLedger selected an EVM-compatible Layer 2 blockchain infrastructure. Rather than allocating extensive resources toward building a proprietary Layer 1 chain, the team chose to adopt a Layer 2 solution—allowing it to focus on core AI platform development. By leveraging Optimistic Rollup (OP Rollup) technology, OpenLedger achieves both scalability and security, while gaining access to Ethereum’s robust ecosystem and its vast pool of Solidity developers. Given the scarcity of engineers with expertise in both AI and blockchain, the decision to use Solidity—the most widely adopted smart contract language—represents a practical strategy to accelerate developer onboarding and ecosystem growth. This approach enables OpenLedger to rely on proven infrastructure while dedicating more resources to building differentiated, AI-native services.
One of OpenLedger’s ambitions is to create the “YouTube moment for AI data”—a platform where contributors are rewarded whenever their expertise is embedded into AI models. Much like YouTube shares ad revenue with creators based on views, OpenLedger seeks to compensate data contributors as their inputs are used in model training and inference. However, unlike YouTube—where views are easy to count—measuring the contribution of individual data to AI models is far more complex. This leads to the central technical challenge: how does OpenLedger quantify and reward data contribution?
Before tracking contributions, the platform must first secure the data that powers its models. At the heart of OpenLedger’s data architecture is DataNets—a decentralized infrastructure designed to collect, verify, and distribute high-quality, domain-specific datasets essential for training Specialized Language Models (SLMs). DataNets form the foundation of OpenLedger’s Data Intelligence Layer, the first phase of its testnet rollout.
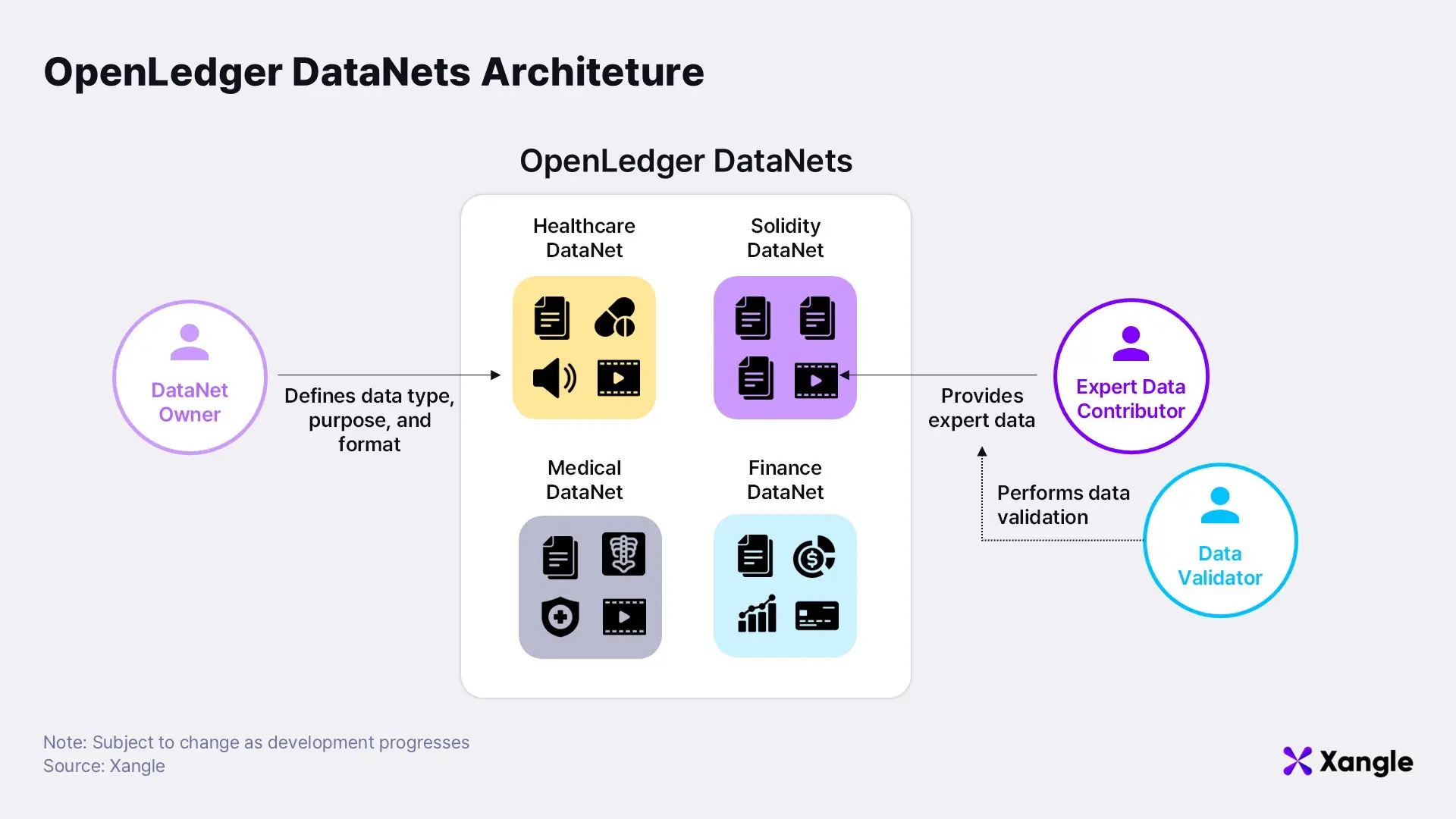
Each DataNet functions as a decentralized repository, allowing experts to contribute validated datasets tailored to specific domains. Every DataNet defines standards for data formats and validation methods. Validated submissions are then securely stored in a distributed manner. Three core roles govern the DataNets ecosystem:
Beyond being decentralized repositories, DataNets also function as Data DAOs (Decentralized Autonomous Organizations). Validators use token staking to align incentives and ensure data quality, while all contribution and usage histories are immutably recorded on-chain. OPEN token holders can participate in governance by voting on decisions related to model development funding, AI agent policies, network upgrades, and treasury allocation. Staking not only enforces accountability but also grants participants access to rewards and priority features.
Despite still being in its testnet phase, OpenLedger has already launched DataNets across a diverse range of domains. These include: Solidity DataNet – Datasets specific to Ethereum development, Data Intelligence DataNet – Continuously updated real-time data, DePIN DataNet – IoT and physical infrastructure datasets, Web3 Trading DataNet – On-chain financial and trading data, and Healthcare DataNet – Medical and clinical datasets. Additional DataNets are in development for fields such as intellectual property, content creation, software development, and investment.
Guided by the principle of quality over quantity, DataNets ensure that AI models are not trained on sheer volume alone, but on verified, high-quality data. Unlike general-purpose models, which rely on web-scraped data that is often noisy or unreliable, OpenLedger’s AI models are grounded in domain expertise. This focus is central to building accurate, trustworthy, and specialized models—aligned with OpenLedger’s mission to deliver value in professional, high-stakes contexts.
The primary technical challenge in realizing Payable AI is solving the data attribution problem—that is, accurately determining how specific datasets influence AI outputs, and designing a mechanism that ensures contributors are fairly compensated based on that impact. While platforms like YouTube rely on measurable engagement metrics (e.g., views, watch time) to distribute revenue to creators, AI models present a more complex scenario. Tracing how data influences model responses is far less transparent.
This complexity stems from how large AI models function. Language models like GPT-4 operate as massive neural networks with billions—or even trillions—of parameters, processing enormous volumes of training data. These systems exhibit a “black box” nature, making it nearly impossible to pinpoint which training examples shaped specific outputs. Unlike simple memorization, these models learn abstract patterns, meaning the relationship between input and output is distributed and nonlinear. To address this, OpenLedger developed a cryptographic mechanism called Proof of Attribution (PoA).
PoA is designed to link individual data contributions to model responses in a transparent and verifiable manner. Consider an example: Professor Kim, a dermatologist, contributes a dataset on rare skin conditions to OpenLedger’s Healthcare DataNet. Months later, a physician asks a medical-specialized SLM deployed on OpenLedger: “Do these symptoms indicate a rare skin disease?” The model generates an accurate response—one that partially derives from Professor Kim’s contributed data.
In this scenario, the PoA system functions much like an academic citation engine. When the model produces an answer, PoA automatically detects that Professor Kim’s data played a significant role in the result. This link is immutably recorded on the blockchain, and Professor Kim is automatically rewarded in $OPEN tokens. OpenLedger refers to this as micro-rewarding—a fine-grained, usage-based incentive structure. If Kim’s dataset continues to inform thousands of future queries, he will receive recurring rewards, similar to how a single YouTube video can generate ongoing ad revenue from repeated views. However, PoA distinguishes itself by rewarding contributors based not on exposure, but on measurable utility and influence.
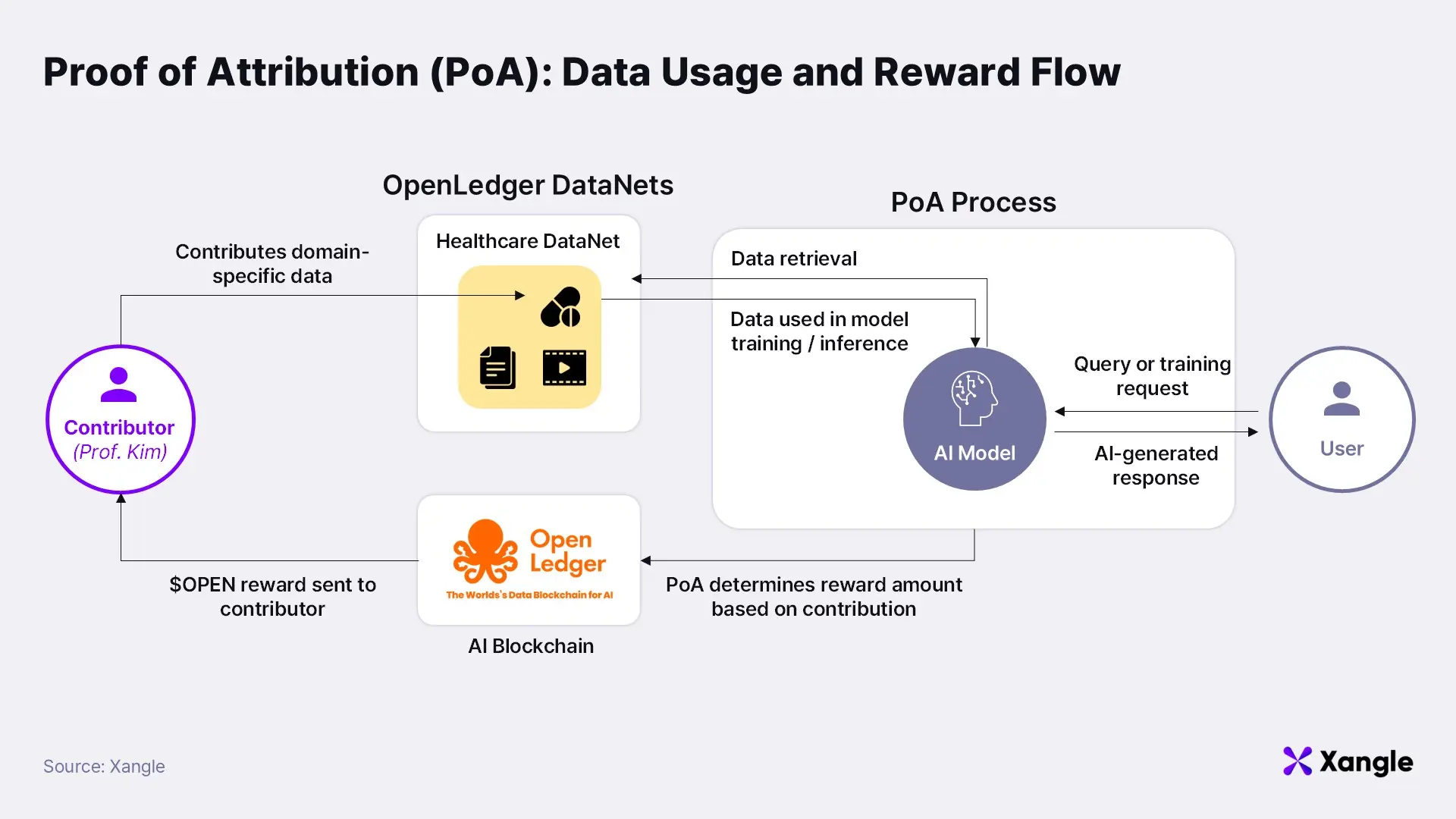
That said, current technological limitations prevent PoA from being applied effectively to massive models like GPT-4. With billions of parameters and vast training corpora, it’s nearly impossible to trace the impact of individual data points. For this reason, OpenLedger focuses on lightweight, specialized models (SLMs), which are more compatible with fine-grained attribution. Notably, two techniques commonly used in SLM tuning—Retrieval-Augmented Generation (RAG) and LoRA (Low-Rank Adaptation)—provide an ideal environment for PoA implementation:
OpenLedger’s PoA system evaluates data influence using two key dimensions:
The system combines these metrics to generate a composite influence score, which forms the basis for allocating rewards. All data usage and contribution events are logged on-chain, ensuring transparency and auditability. To promote data quality, PoA also incorporates a slashing mechanism—contributors of low-quality or malicious data risk losing staked tokens, thereby reinforcing a culture of accountability.
Having established domain-specific DataNets and an accurate data attribution technology (PoA), OpenLedger next provides technical infrastructure enabling users to practically develop and deploy specialized AI models. Specifically, two core infrastructures—ModelFactory and OpenLoRA—support streamlined SLM development, serving, and external integrations, laying the groundwork for practical, easy-to-use AI model creation and efficient deployment.
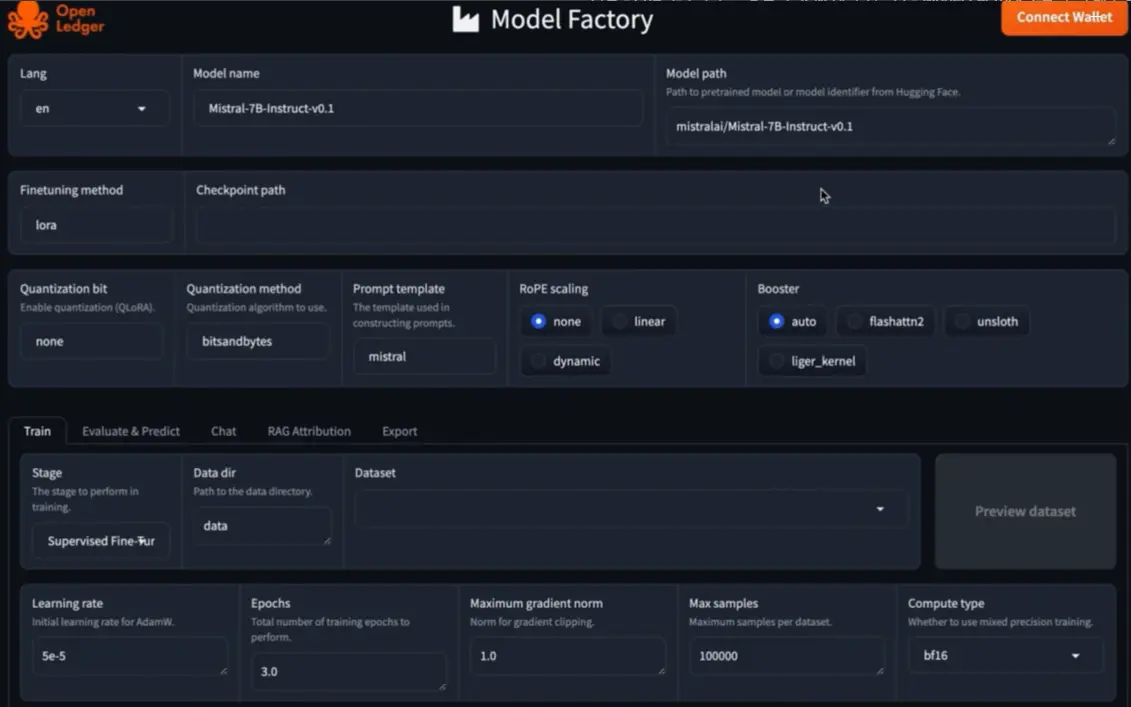
ModelFactory is a user-friendly, no-code tool designed to simplify the tuning of large language models (LLMs). Its primary goal is to eliminate the largest barrier in traditional AI development—complex coding—by allowing users to develop specialized AI models without any programming knowledge.
Traditionally, tuning AI models required technical proficiency in programming and command-line tools, making it virtually inaccessible to non-engineers. ModelFactory eliminates this barrier by offering a fully graphical interface. Experts such as doctors, lawyers, and financial analysts can now train AI models with their own domain-specific knowledge—without needing any machine learning background.
 Source: OpenLedger
Source: OpenLedger
The tuning process in ModelFactory follows a streamlined, intuitive flow:
A standout feature of ModelFactory is its integration of RAG-based (Retrieval-Augmented Generation) contribution tracking. RAG enables the model to retrieve relevant information from external databases during inference. ModelFactory tracks exactly which datasets were used during this process and cites them accordingly. When combined with OpenLedger’s PoA framework, this provides a transparent, verifiable mechanism for rewarding data contributors whose knowledge directly influences model outputs.
 Source: OpenLedger
Source: OpenLedger
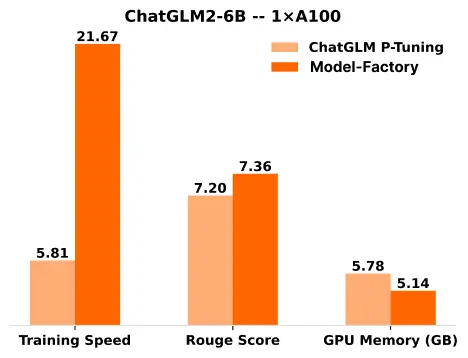
Performance benchmarks published by OpenLedger highlight ModelFactory’s efficiency. Its LoRA-based tuning approach delivers up to 3.7x faster training compared to traditional P-Tuning. While P-Tuning improves model performance by adjusting prompt parameters without full retraining, it still demands considerable computational power. LoRA, in contrast, leaves the foundational model weights untouched and trains only a small number of adaptive parameters—significantly reducing resource requirements.
ModelFactory effectively democratizes the model development process—shifting AI from the hands of technical specialists to the broader community of domain experts. By empowering professionals to embed their knowledge directly into AI models, the platform accelerates the creation of more accurate, specialized, and trustworthy models. These models are seamlessly deployed and served using OpenLoRA, the serving infrastructure detailed in the next section.
Once specialized models are developed, an efficient and scalable serving infrastructure becomes essential. This is where OpenLoRA plays a pivotal role. As a serving framework purpose-built for SLMs, OpenLoRA enables the deployment of thousands of finely tuned LoRA models on a single GPU, dramatically improving the economic feasibility of large-scale AI deployment.
Traditionally, serving multiple domain-specific models simultaneously required dedicating separate GPU infrastructure to each model instance—leading to substantial operational costs. For example, running distinct models for medical, legal, and finance applications would typically require three separate servers. OpenLoRA eliminates this inefficiency through a lightweight, modular architecture.
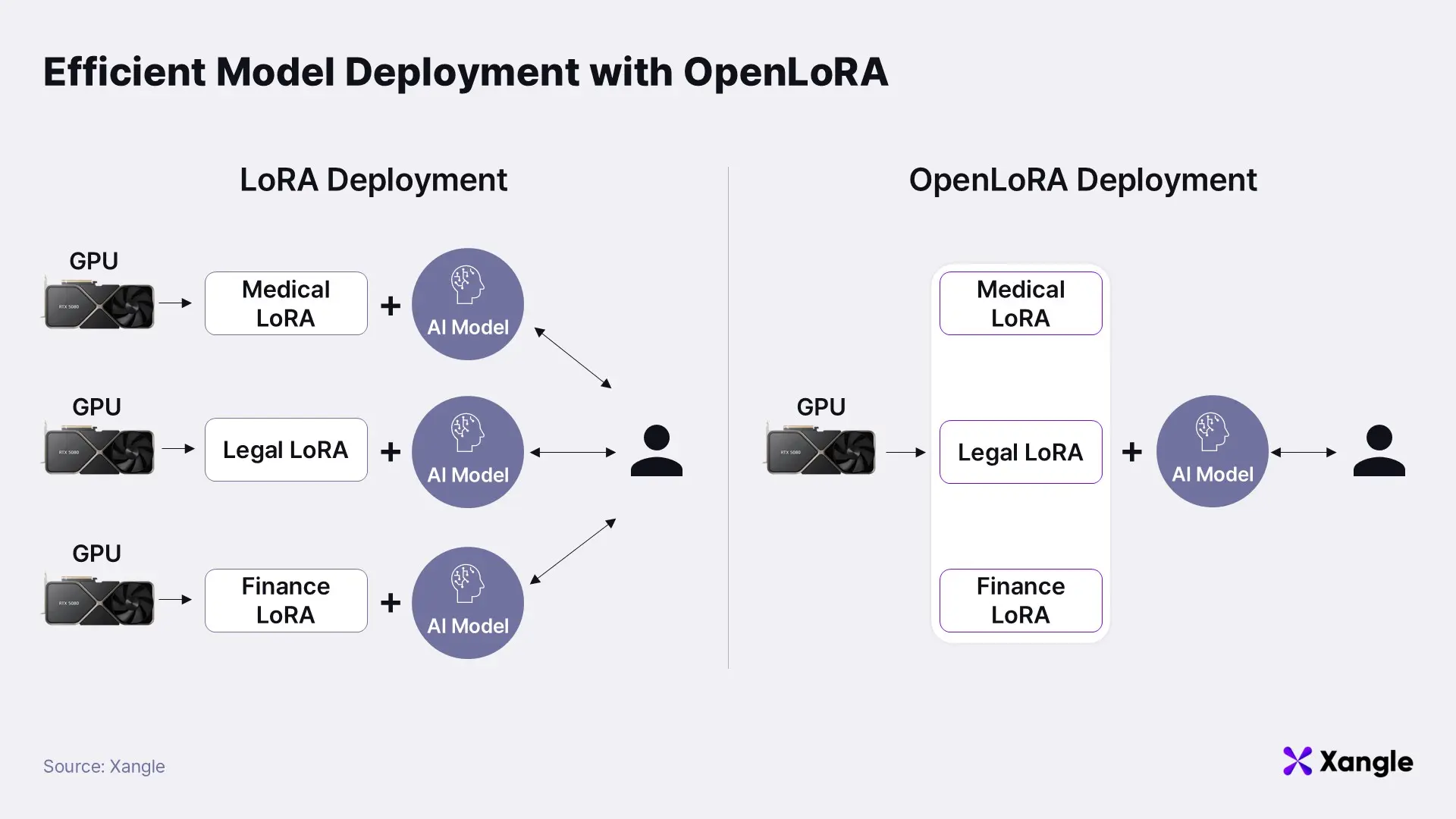
The framework operates on three core principles:
This dynamic composition strategy is akin to wearing a single outfit while swapping accessories to match different occasions—offering tailored responses without incurring the memory overhead of running multiple models in parallel. Where a traditional setup might require 1,000GB of memory to serve 100 individual 10GB models, OpenLoRA can deliver the same service with only ~20GB—a single 10GB base model and 100 adapters, each roughly 100MB. This yields up to a 98% reduction in memory usage.
The flexibility of OpenLoRA also allows AI agents to contextually switch between specialized models based on the nature of the user query. A question like “What does this rash indicate?” triggers the use of a dermatology-specific model, while “What’s the legal risk in this contract?” automatically activates a law-specific model—ensuring domain-appropriate answers without delay or human intervention.
Beyond performance, this innovation dramatically reduces the cost of AI model deployment. What once required a fleet of servers can now be handled by just one or two, making SLM deployment viable even at massive scales. In this way, OpenLoRA provides the foundational infrastructure for OpenLedger’s broader vision: a future where thousands of domain-specific AI models operate in parallel, each delivering deep, targeted expertise.
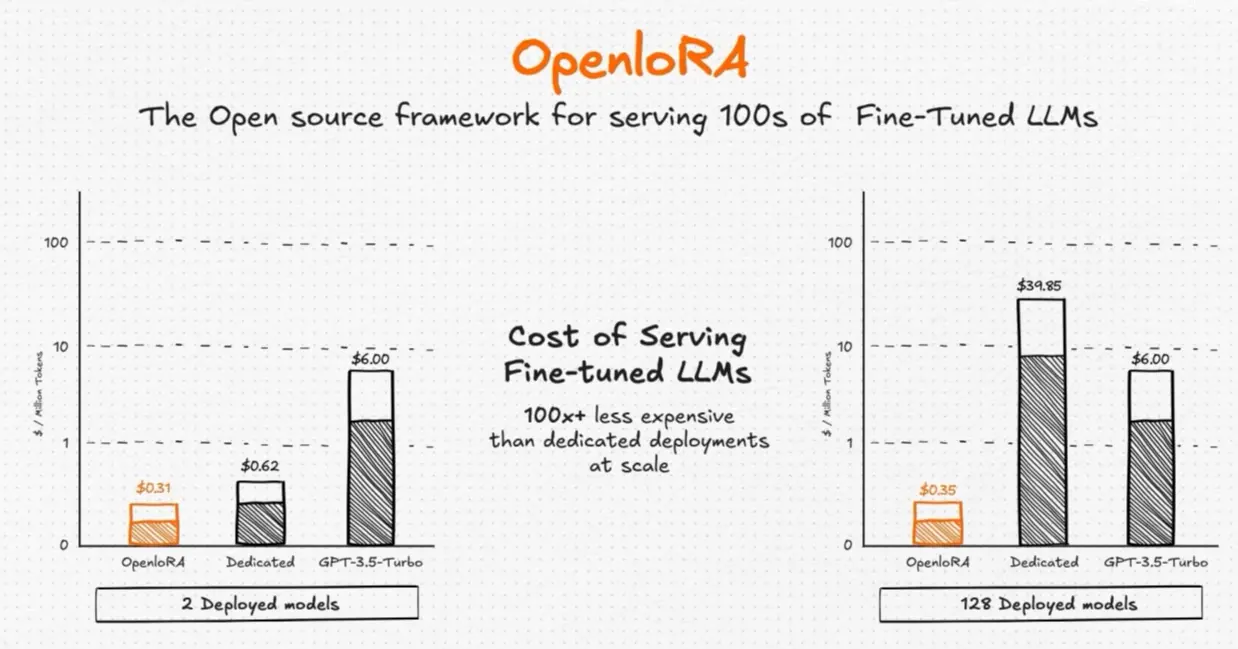 Source: OpenLedger
Source: OpenLedger
To ensure that OpenLedger’s technical architecture functions as intended, it must be supported by a robust economic model and a well-structured incentive system. At the core of this framework is the $OPEN token, whose utility spans across governance, staking, contributor rewards, and infrastructure access. The following section outlines how $OPEN powers the platform’s tokenomics and supports its long-term sustainability.
The utility of $OPEN extends far beyond its role as a medium of exchange. It serves as the economic backbone of the OpenLedger platform—linking data contributors, AI developers, validators, and end users in a unified incentive structure. The effectiveness of any token economy depends on how broadly and meaningfully the token can be applied. OpenLedger delivers on this through several core mechanisms.
$OPEN functions as the native gas token on OpenLedger’s Layer 2 blockchain, reducing dependence on Ethereum while providing a transaction environment optimized for AI applications. It also plays a central role in the Proof of Attribution (PoA) system, facilitating proportional rewards for contributors based on their impact—whether in the form of data, model development, or validation.
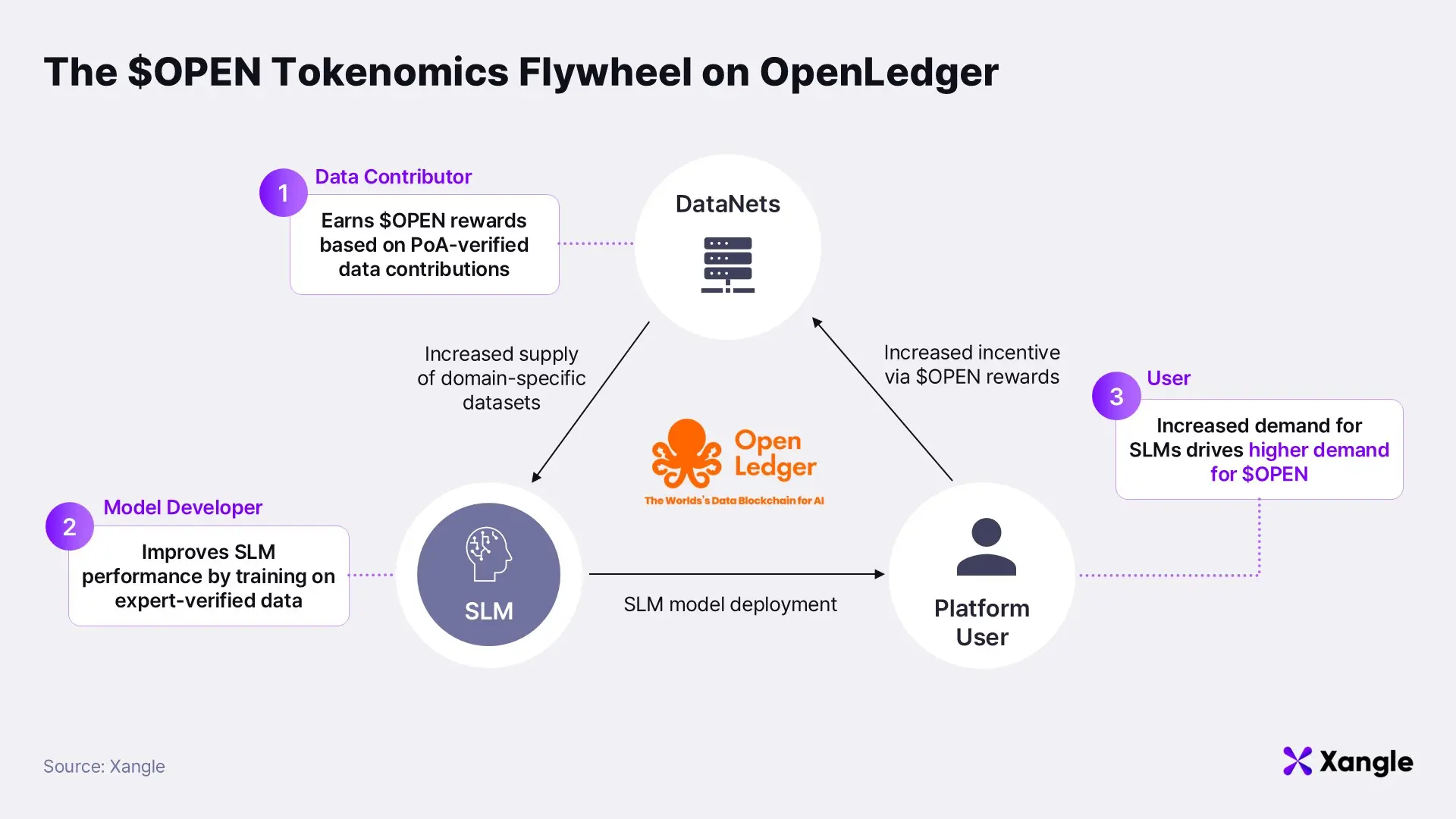
A defining feature of this incentive model is its continuous reward mechanism for data contributions. In contrast to the traditional approach—where AI training data is sourced via one-off purchases or web scraping—OpenLedger rewards data providers each time their contribution is used in model training or inference. This marks a paradigm shift: the recognition of “data labor” as an economic activity. By aligning incentives with ongoing usage rather than one-time extraction, OpenLedger offers a powerful catalyst for improved data quality and ongoing participation.
The $OPEN token supports smooth interaction between AI models and the Web3 economy by forming liquidity pools for model-specific tokens. Users can stake $OPEN on model bonding curves, contributing to model adoption and long-term sustainability. Operating AI models on the platform also requires $OPEN to be staked—models delivering more critical services demand higher staking levels.
This staking mechanism introduces financial accountability as a way to ensure service quality. At a time when trust and safety in AI systems are increasingly important, applying economic penalties to models that produce misinformation or harmful outputs can serve as a self-regulating quality control system—one governed by market principles rather than centralized authorities.
By combining these elements, the $OPEN token becomes a central instrument for facilitating value exchange, incentivizing high-quality contributions, and governing platform growth. This stands in sharp contrast to the Web2 model, where value was often extracted from user-generated data without compensation. OpenLedger’s tokenomics, by design, ensures a more equitable distribution of value—a core principle of Web3.
That said, the effectiveness of this economic model is contingent on several enabling conditions. These are explored in the next section.
Realizing OpenLedger’s vision of the “YouTube moment for AI data” depends on the successful creation of a self-sustaining, token-based economic flywheel. For the $OPEN token economy to function effectively, several foundational conditions must be in place.
As with any platform business, reaching a minimum threshold of active participants—data contributors, model developers, and users—is essential. A dynamic ecosystem of value exchange cannot exist without it. In the early stages, OpenLedger should focus on “core domains” where active communities already exist and where the willingness to share and monetize data is high—such as Web3, DeFi, and crypto-native sectors. Targeting these domains will help the platform achieve network critical mass more rapidly and build early momentum.
The success of the platform hinges on the availability of high-quality data. In practice, acquiring such data is likely to be the most significant early hurdle. For model developers to pay for datasets, there must be credible evidence that the data meaningfully enhances model performance. Demonstrating this link between input and output will be vital.
Equally important is the creation of a robust data validation layer. A pool of qualified validators—experts capable of assessing data quality within specific domains—must be recruited and retained. Establishing this validator base will require time, effort, and appropriate economic incentives. Additionally, OpenLedger must define clear and consistent standards for evaluation and introduce mechanisms to ensure fairness and transparency in the validation process. Designing this structure is a key challenge in the platform’s early lifecycle.
To ensure a continuous supply of high-quality data, contributors must trust that they will be compensated fairly and consistently for their efforts. The platform must offer clear, predictable reward mechanisms—especially during the transition from testnet (with point-based incentives) to mainnet (with token-based rewards). Transparent value attribution and compensation logic are critical for building long-term contributor engagement.
Finally, cost-efficiency must be maintained throughout the AI model lifecycle. SLM development and operation should remain economically viable, especially as the platform scales. Technologies like OpenLoRA—which drastically reduce the computational resources needed to serve domain-specific models—play a vital role in making specialized AI development accessible and scalable.
When these conditions are met, OpenLedger can establish a positive feedback loop driven by the utility of the $OPEN token. Contributors, developers, and users will reinforce one another’s incentives, propelling platform growth. However, for this system to take hold, OpenLedger must first overcome early-stage challenges—especially those tied to data quality assurance and validator infrastructure. Addressing these effectively will determine whether OpenLedger matures into a sustainable, SLM-centric AI ecosystem.
This report has explored OpenLedger’s vision, technical framework, and tokenomics—presenting a compelling response to some of the most pressing challenges facing the AI industry today. By centering its platform around Specialized Language Models (SLMs), OpenLedger proposes a decentralized AI architecture that prioritizes three critical outcomes: improved data quality, enhanced domain-specific intelligence, and a more equitable distribution of economic value.
As the AI industry matures, more projects are evolving beyond generic infrastructure to embrace precise, application-driven strategies. OpenLedger is no exception. With innovations such as PoA, ModelFactory, and OpenLoRA, the project outlines a clear and technically feasible roadmap toward a sustainable, Web3-native AI ecosystem.
However, this path is not without its challenges. Integrating tokenized economics introduces macro-level volatility that cannot be easily mitigated—especially given the unpredictable nature of cryptocurrency markets, regulatory fluctuations, and varying levels of Web3 adoption. No matter how well-designed the technical architecture or incentive mechanisms may be, token price swings and ecosystem dynamics will remain key risk factors. To navigate these complexities, Web3 AI projects like OpenLedger must be strategically prepared. Long-term success will depend not only on core platform innovation, but also on proactive management of DeFi interoperability, cross-chain integration, and token liquidity—all foundational elements of a thriving decentralized economy.
Still, OpenLedger’s vision remains highly compelling: a future in which no single model dominates, but rather thousands of specialized AI agents operate collaboratively—each excelling within its own domain. It’s a vision aligned with the trajectory toward a truly personalized and decentralized intelligence layer, and one that resonates with our collective aspiration for an AI assistant as capable and context-aware as Jarvis. As the AI and Web3 industries continue to converge, OpenLedger stands at a critical intersection. Whether it can successfully balance technological ambition with market realities remains to be seen—but it is a journey well worth watching.